Similarly, here driver component of spark job will not run on the local machine from which job is submitted. 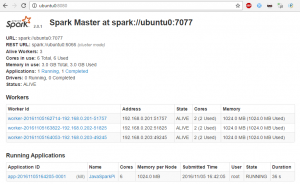 Go to the Spark History user interface and then open the incomplete application. Assign NAT Network Adapter for Master and worker nodes. These two containers share a custom bridge network. The machine on which the Spark Standalone cluster manager runs is called the Master Node. The resources are allocated by Master. It uses the "Workers" running throughout the cluster for the creation of Executors for the "Driver". After that, the Driver runs tasks on Executors. Spark Driver is the program that runs on the master node of the machine and declares transformations and actions on data RDDs. I can't find any firewall(ufw) and iptables rule. These are stored in spark-defaults.conf on the cluster head nodes. This architecture deploys an Apache Spark cluster on Oracle Cloud Infrastructure using the manager/worker model. Value Description; cluster: In cluster mode, the driver runs on one of the worker nodes, and this node shows as a driver on the Spark Web UI of your application. It is the central point and the entry point of the Spark Shell (Scala, Python, and R). Each application has its own executors. Since the internet is needed for the nodes, the NAT network is used. not available to garner authentication information from the user at com.
Go to the Spark History user interface and then open the incomplete application. Assign NAT Network Adapter for Master and worker nodes. These two containers share a custom bridge network. The machine on which the Spark Standalone cluster manager runs is called the Master Node. The resources are allocated by Master. It uses the "Workers" running throughout the cluster for the creation of Executors for the "Driver". After that, the Driver runs tasks on Executors. Spark Driver is the program that runs on the master node of the machine and declares transformations and actions on data RDDs. I can't find any firewall(ufw) and iptables rule. These are stored in spark-defaults.conf on the cluster head nodes. This architecture deploys an Apache Spark cluster on Oracle Cloud Infrastructure using the manager/worker model. Value Description; cluster: In cluster mode, the driver runs on one of the worker nodes, and this node shows as a driver on the Spark Web UI of your application. It is the central point and the entry point of the Spark Shell (Scala, Python, and R). Each application has its own executors. Since the internet is needed for the nodes, the NAT network is used. not available to garner authentication information from the user at com.
-e
spark-class org.apache.spark.deploy.worker.Worker spark://
Two Ethernet networks must be connected.
If What makes a server the Master node is only the fact that it is running the master service, while the other machines are running the slave service and are pointed to that first master. Master is per cluster, and Driver is per application. RDDs are collection of data items that are split into partitions and can be stored in-memory on workers nodes of the spark cluster architecture. The master is the driver that runs the main() program where the spark context is created.
Select the machine -> Settings.  For standalone/yarn clusters, Spark currently supports two deploy modes. This Docker image provides Java, Scala, Python and R execution environment. There are two types of nodes in Kubernetes: Master nodes; Worker nodes; Master nodes are responsible for maintaining the state of the Kubernetes cluster, whereas worker nodes are responsible for executing your Docker containers. The central coordinator is called Spark Driver and it communicates with all the Workers. security. Go to bin folder, run script to start worker node:./spark-class org.apache.spark.deploy.worker.Worker spark://localhost.localdomain:7077. The default value of the driver node type is the same as the worker node type. This guide provides step by step instructions to deploy and configure Apache Spark on the real multi-node cluster. The default number of executors and the executor sizes for each cluster is calculated based on the number of worker nodes and the worker node size. Apache Spark Executor Logs : Spark Executors are worker nodes-related processes that are in charge of running individual tasks in a given Spark job. 1. So far we started our Master node and one Worker node in the same machine. The components of a Spark application are the Driver, the Master, the Cluster Manager, and the Executor (s), which run on worker nodes, or Workers. All this, and more, plus a growing list of capabilities.UE5 Blueprint Tutorials for Beginners in 2022. Objective. The provided nodes will allow you to read, write, copy, and delete files. This Docker image provides Java, Scala, Python and R execution environment. Toggle navigation export SPARK_WORKER_CORES=6 export SPARK_MASTER_HOST=192.168.0.106 export SPARK_LOCAL_IP=192.168.0.201 Log from a The master and each worker has its own web UI that shows cluster and job statistics. cassandra Spark Worker Nodes starting but not showing in WebUI I am trying to setup a small 3 node Spark cluster using some Raspberry Pi's and my main desktop but can't seem to get the . Spark Architecture. By default the sdesilva26/spark_worker:0.0.2 image, when run, will try to join a Spark cluster with the master node located at spark://spark-master:7077. master is the Spark master connection URL, the same used by Spark worker nodes to connect to the Spark master node; config is a general Spark configuration for standalone mode . Start Master and Worker nodes from VirtualBox. Description of the illustration spark-oci-png.png. 2. A single node can run multiple executors and executors for an application can span multiple worker nodes. Hence, this spark mode is basically cluster mode. Apache Spark Executor Logs: Spark Executors are worker nodes-related processes that are in charge of running individual tasks in a given Spark job. Each Worker node consists of one or more Executor(s) who are responsible for running the Task. As we can see that Spark follows Master-Slave architecture where we have one central coordinator and multiple distributed worker nodes. Extending to other great answers, I would like to describe with few images. For more information, see Plan and Configure Master Nodes. client mode is majorly used for interactive and debugging purposes. Each Driver or Nodes are nothing but a JVM (Java Virtual Machine). It has a manager node and three worker nodes, running on compute instances. This means the master node stores where the information about the data. The driver node also maintains the SparkContext and interprets all the commands you run from a notebook or a library on the cluster, and runs the Apache Spark master that coordinates with the Spark executors. In Spark Standalone mode, there are master node and worker nodes. Please note that the amount of CPU cores and memory to be reserved by the worker are defined in Dockerfile_worker and can be optionally overwritten by environment variables. : client: In client mode, the driver runs locally from where you are submitting your application using spark-submit command. Worker Node.
For standalone/yarn clusters, Spark currently supports two deploy modes. This Docker image provides Java, Scala, Python and R execution environment. There are two types of nodes in Kubernetes: Master nodes; Worker nodes; Master nodes are responsible for maintaining the state of the Kubernetes cluster, whereas worker nodes are responsible for executing your Docker containers. The central coordinator is called Spark Driver and it communicates with all the Workers. security. Go to bin folder, run script to start worker node:./spark-class org.apache.spark.deploy.worker.Worker spark://localhost.localdomain:7077. The default value of the driver node type is the same as the worker node type. This guide provides step by step instructions to deploy and configure Apache Spark on the real multi-node cluster. The default number of executors and the executor sizes for each cluster is calculated based on the number of worker nodes and the worker node size. Apache Spark Executor Logs : Spark Executors are worker nodes-related processes that are in charge of running individual tasks in a given Spark job. 1. So far we started our Master node and one Worker node in the same machine. The components of a Spark application are the Driver, the Master, the Cluster Manager, and the Executor (s), which run on worker nodes, or Workers. All this, and more, plus a growing list of capabilities.UE5 Blueprint Tutorials for Beginners in 2022. Objective. The provided nodes will allow you to read, write, copy, and delete files. This Docker image provides Java, Scala, Python and R execution environment. Toggle navigation export SPARK_WORKER_CORES=6 export SPARK_MASTER_HOST=192.168.0.106 export SPARK_LOCAL_IP=192.168.0.201 Log from a The master and each worker has its own web UI that shows cluster and job statistics. cassandra Spark Worker Nodes starting but not showing in WebUI I am trying to setup a small 3 node Spark cluster using some Raspberry Pi's and my main desktop but can't seem to get the . Spark Architecture. By default the sdesilva26/spark_worker:0.0.2 image, when run, will try to join a Spark cluster with the master node located at spark://spark-master:7077. master is the Spark master connection URL, the same used by Spark worker nodes to connect to the Spark master node; config is a general Spark configuration for standalone mode . Start Master and Worker nodes from VirtualBox. Description of the illustration spark-oci-png.png. 2. A single node can run multiple executors and executors for an application can span multiple worker nodes. Hence, this spark mode is basically cluster mode. Apache Spark Executor Logs: Spark Executors are worker nodes-related processes that are in charge of running individual tasks in a given Spark job. Each Worker node consists of one or more Executor(s) who are responsible for running the Task. As we can see that Spark follows Master-Slave architecture where we have one central coordinator and multiple distributed worker nodes. Extending to other great answers, I would like to describe with few images. For more information, see Plan and Configure Master Nodes. client mode is majorly used for interactive and debugging purposes. Each Driver or Nodes are nothing but a JVM (Java Virtual Machine). It has a manager node and three worker nodes, running on compute instances. This means the master node stores where the information about the data. The driver node also maintains the SparkContext and interprets all the commands you run from a notebook or a library on the cluster, and runs the Apache Spark master that coordinates with the Spark executors. In Spark Standalone mode, there are master node and worker nodes. Please note that the amount of CPU cores and memory to be reserved by the worker are defined in Dockerfile_worker and can be optionally overwritten by environment variables. : client: In client mode, the driver runs locally from where you are submitting your application using spark-submit command. Worker Node.
auth. In addition, here spark job will launch driver component inside the cluster. It consists of various types of cluster managers such as Hadoop YARN, Apache Mesos and Standalone Scheduler. To do this use To encrypt Spark connections for all components except the web UI, enable spark_security_encryption_enabled. The port can be changed either in the configuration file or via command-line options. I know this is an old question and Sean's answer was excellent. My writeup is about the SPARK_WORKER_INSTANCES in MrQuestion's comment. If you use The plugin also provides nodes for creating, deleting, copying, and searching directories.
Value Description; cluster: In cluster mode, the driver runs on one of the worker nodes, and this node shows as a driver on the Spark Web UI of your application. I suggest reading the Spark cluster docs first, but even more so this Cloudera blog post explaining these modes. cluster mode is used to run production jobs. So in the sixth blog of the series, we will be building two node cluster containing single master and single worker.You can access all the posts in the series here. They are started at the beginning of a Spark application, and typically run for the entire lifetime of an application. sun.
Executors are worker nodes processes in charge of running individual tasks in a given Spark job. If one of the master nodes fails, Amazon EMR automatically fails over to a standby master node and replaces the failed master node with a new one with the same configuration and bootstrap actions. Describe the bug Hi, I am trying to build spark cluster with multipass on my mac but connection between master and worker isn't established. Setting it to enabled turns on authentication between the Spark Master and Worker nodes, and allows you to enable encryption. Here, we are matching the executor memory, that is, a Spark worker JVM process, with the provisioned worker node memory. cluster mode is used to run production jobs. Our setup will work on One Master node (an EC2 Instance) and Three Worker nodes. And with a Spark standalone cluster with cluster deploy mode, you can also specify --supervise to make sure that the driver is automatically restarted if it fails with non-zero exit code . Spark master JVM acts as a cluster manager in. Is Worker Node in Spark is same as Slave Node? Worker node refers to node which runs the application code in the cluster. Worker Node is the Slave Node. Master node assign work and worker node actually perform the assigned tasks. Worker node processes the data stored on the node, they report the resources to the master.
A simple spark standalone cluster for your testing environment purposses. It is nice to work with Spark locally when doing exploratory work or when working with a small data set.Impact of Spark Re-partitioning. In "client" mode, the submitter launches the driver outside of the cluster. Spark can run in Local Mode on a single machine or in Cluster-Mode on different machines connected to distributed computing.
Hence, in that case, this spark mode does not work in a good manner. Here Spark Driver Programme runs Master: A master node is an EC2 instance.
Each worker instance will use two cores. The number of executors for a spark application can be specified inside the SparkConf or via the flag num-executors from command-line.
A process launched for an application on a worker node, that runs tasks and keeps data in memory or disk storage across them. A docker-compose up away from you solution for your s Both are the resource manager.When you start your application or submit your application in cluster mode a Driver will start up wherever you do ssh to start that application. Navigate to Network -> Adapter1 and set as below: Assign NAT Network Adapter for Master and worker nodes. client mode is majorly used for interactive and In "cluster" mode, the framework launches the driver inside of the cluster. By default, you can access the web UI for the master at port 8080. Figure 3.1 shows all the Spark components in the context of a Spark Standalone application. In client mode, the driver is launched in the same process as the client that submits the application. The following diagram illustrates this reference architecture. The worker nodes do the actual computing and stores the real data whereas on master we have metadata. spark-submit \--class
They are launched at the beginning of a Spark application and typically run for the entire lifetime of an application. It handles resource allocation for multiple jobs to the spark cluster. The ingress, and ingress-dns addons are currently only supported on Linux. spark standalone worker not able to connect driver. Steps to install Apache Spark on multi-node cluster. Spark Cluster with Docker & docker-compose General. - GitHub - hellgate75/apache-spark: Docker Image for Apache Spark Master/Worker Node. The number of cores to use on each executor. The master node is no longer a potential single point of failure with this feature. They are started at the beginning of a Spark application, and typically run for the entire lifetime of an application. Master node assigns various functions to the worker nodes and manages the resources. SPARK_WORKER_INSTANCES=3 SPARK_WORKER_CORES=2 ./sbin/start-slaves.sh. We will use our Master to run the Driver Program and deploy it in Standalone mode using the default Cluster Manager. I have two docker containers that have spark and one is running as master and anther as worker. See #7332Create a spark-master container inside of the bridge network. Spark is used for big data analysis and developers normally need to spin up multiple machines with a company like databricks for production computations. 1. In one of the worker nodes, we will install RStudio server. Could be scaled. spark-worker-1: A worker node, connecting to the master. Also it is possible to manually start workers and connect to Sparks master node. Glue 1.0 jobs can be directly converted to Glue 2.0 Glue -Change the deafult configs for lesser cost. EXECUTORS. - GitHub - hellgate75/apache-spark: Docker Image for Apache Spark Master/Worker Node. Docker Image for Apache Spark Master/Worker Node. The number of executors for a spark application can be specified inside the SparkConf or via the flag num-executors from command-line. Since internet is needed for the nodes, NAT network is used; Select Adapter 2 and Configure as below; Verify network configuration. 28. Here is the basic diagram of the components of a cluster. module. It then interacts with the cluster manager to schedule the job execution and perform the tasks. The Four main components of Spark are given below and it is necessary to understand them for the complete framework. If you change the name of the container running the Spark master node (step 2) then you will need to pass this container name to the above command, e.g. Once they have run the task they send the results to the driver. Select Adapter 2 and Configure as below: Verify network configuration Apache Spark follows a master/slave architecture, with one master or driver process and more than one slave or worker processes. Cause. A node could be a physical machine or a virtual machine on a cloud provider, such as an EC2 instance. An executor stays up for the duration of the Spark Application and runs the tasks in multiple threads. : client: In client mode, the driver runs locally where you are submitting your application from. The most common cause of this is decommissioning over half of the Spark Cluster. An executor stays up for the duration of the Spark Application and runs the tasks in multiple threads. Driver JVM will contact to the SparK Master for executors (Ex) and in standalone mode Worker will start the Ex. In simple terms, a driver in Spark creates SparkContext, connected to a given Spark Master. Architecture. This will launch three worker instances on each node. 2 min read. I suggest reading the Spark cluster docs first, but even more so this Cloudera blog post explaining these modes. Notebook is the interface where programs can be written in different languages supported by Apache Spark like Python, Scala etc. When we submit a Spark JOB via the Cluster Mode, Spark-Submit utility will interact with the Resource Manager to Start the Application Master.
As Lan was saying, the use of multiple worker instances is only relevant in standalone mode. There are two reasons why you want to have multiple in Answer (1 of 2): As we know, Spark runs on Master-Slave Architecture. Sparks standalone mode offers a web-based user interface to monitor the cluster. As a next step we will be building two node spark standalone cluster using that image. Spark Driver Master Node of a Spark Application. Spark Cluster Mode. This Docker image provides Java, Scala, Python and R execution environment. Get started with Blueprints in Unreal Engine 5!