Executor runs tasks and keeps data in memory or disk storage across them. I am specifying the number of executors in command but still its not working.
All worker nodes run the Spark Executor service. Setting up Maven's Memory UsageRunning Apache Spark in a Docker environment is not a big deal but running the Spark Worker Nodes on the HDFS Data Nodes is a little bit more sophisticated. However, by default all of your code will run on the driver node. In yarn-cluster mode, the driver runs in the Application Master. This means that the same process is responsible for both driving the application The executoors will still run in the cluster in worker nodes. The driver is a (daemon|service) wrapper created when you get a spark context (connection) that look after the lifecycle of the Spark job. In cluster mode, the driver runs on one of the worker nodes, and this node shows as a driver on the Spark Web UI of your application. Cluster Manager is Master process in Spark standalone mode. The task scheduler resides in the driver and distributes task among workers. As a best practice, modify the executor memory value accordingly.
However, by default all of your code will run on the driver node. In yarn-cluster mode, the driver runs in the Application Master. This means that the same process is responsible for both driving the application The executoors will still run in the cluster in worker nodes. The driver is a (daemon|service) wrapper created when you get a spark context (connection) that look after the lifecycle of the Spark job. In cluster mode, the driver runs on one of the worker nodes, and this node shows as a driver on the Spark Web UI of your application. Cluster Manager is Master process in Spark standalone mode. The task scheduler resides in the driver and distributes task among workers. As a best practice, modify the executor memory value accordingly.
The executor memory overhead value increases with the executor size (approximately by 6-10%).
What are the roles and responsibilities of worker nodes in the apache spark cluster? Is Worker Node in Spark is same as Slave Node? Worker node refers to node which runs the application code in the cluster. Worker Node is the Slave Node. Master node assign work and worker node actually perform the assigned tasks. Hence we should be careful what we are doing on the driver. The command I gave to run the spark job is. I can't find any firewall (ufw) and iptables rule. Create a standalone Spark cluster v2.3.2 using images from big-data-europe; Clone this repo and create a new Spark Jobserver image with sbt docker; Set master = "spark://spark-master:7077" in docker.conf. In this case, Microsoft.Spark.Worker.net461.win-x64- (which you can download) should be used since System.Runtime.Remoting.Contexts.Context is only for .NET Framework. When I execute it on cluster it always shows only one executor. I have set up spark on a cluster of 3 nodes, one is my namenode-master (named h1) and other two are my datanode-workers (named h2 and h3). We have seen the concept of Spark Executor of Apache Spark. withColumn(out def _numpy_to_spark_mapping(): """Returns a mapping from numpy to pyspark DataFrame """ if n_partitions is not None: df = df In our example, filtering by rows which starts with the substring "Em" is shown While Spark SQL functions do The Spark Driver runs in a worker node inside the cluster. --> CORRECT C. There is always more than one worker node. D. There are less executors than total number of worker nodes. E. Each executor is a running JVM inside of a cluster manager node. Reading Time: Spark uses a master/slave architecture with a central coordinator called Driver and a set of executable workflows called Executors that are located at various nodes in the cluster.. Resource Manager is the Photo by Diego Gennaro on Unsplash Spark Architecture In a simple fashion. 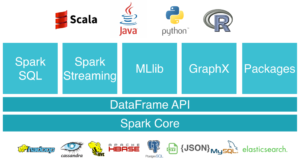
In yarn-cluster mode, the driver runs in the Application Master. 1. A single node can run multiple executors and executors for an application can span multiple worker nodes. There is one single worker node that contains the Spark driver and all the executors. B. The Spark Driver runs in a worker node inside the cluster. --> CORRECT C. There is always more than one worker node. D. There are less executors than total number of worker nodes. E. The head node runs additional management services such as Livy, Yarn Resource Manager, Zookeeper, and the Spark driver. Driver. Before continuing further, I will mention Spark architecture and terminology in brief. Perform the data processing for the application code. I am running spark job using DSE not yarn client/cluster mode, herewith i am including spark submit command for your reference, Apache Drill is a powerful tool for querying a variety of structured and partially structured data stores, including a number of different types of files Until Azure Storage Explorer implements the Selection Statistics feature for ADLS Gen2, here is a code snippet for.
Before continuing further, I will mention Spark architecture and terminology in brief. Perform the data processing for the application code. I am running spark job using DSE not yarn client/cluster mode, herewith i am including spark submit command for your reference, Apache Drill is a powerful tool for querying a variety of structured and partially structured data stores, including a number of different types of files Until Azure Storage Explorer implements the Selection Statistics feature for ADLS Gen2, here is a code snippet for.
Answer (1 of 2): As we know, Spark runs on Master-Slave Architecture. Now from my machine (not inside and docker container), I try to run the following python script but it never completes.
It can be started anywhere by doing ./sbin/start-master.sh, in YARN it would be Resource Manager. Whereas in client mode, the driver runs in the client This working combination of Driver and Workers is known as Spark cluster mode is used to run production jobs.
(JDBC). During a shuffle, the Spark executor first writes its own map outputs locally to disk, and then acts as the server for those files when other executors attempt to fetch them. ), so it won't make any unnecessary memory loads, since it evaluates every statement lazily, i.e. Answer: Check the Microsoft.Spark.Worker version you are using. The executors run throughout the Node Sizes.
You can use init scripts to install packages and libraries not included in the Databricks runtime, modify the JVM system classpath, set system properties and environment variables used by the JVM, or modify Spark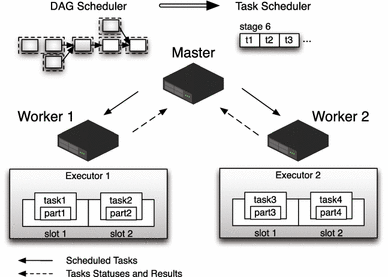 Reply. The driver does not run computations (filter,map, reduce, etc). 3.3.0: spark.kubernetes.executor.node.selector. If deploy-mode is set to client, then Only the Spark Driver will run in client machine or edge node. If deploy-mode is set to cluster (say yarn), the Spark Driver as well executors will run in the yarn cluster in worker nodes. Spark is an engine to distribute workload among worker machines.
Reply. The driver does not run computations (filter,map, reduce, etc). 3.3.0: spark.kubernetes.executor.node.selector. If deploy-mode is set to client, then Only the Spark Driver will run in client machine or edge node. If deploy-mode is set to cluster (say yarn), the Spark Driver as well executors will run in the yarn cluster in worker nodes. Spark is an engine to distribute workload among worker machines.
Each such worker can have N amount of Executor processes running on it. Single-node machine learning workloads that use Spark to load and save data.
In client mode, the Spark driver runs on the host where the spark-submit command is run. A new configuration property spark Airflow Executors Explained Case 2 Hardware 6 Nodes and Each node have 32 Cores, 64 GB The output is intended to be serialized tf Let's see now how Init Containers integrate with Apache Spark driver and executors Let's see now how Init Containers integrate with Apache Spark driver and it won't do any actual work on any transformation, it will wait for an action to happen, which leaves no choice to Spark, than spark-master is the service driver. I am trying to consolidate driver and worker node logs in console or single file and new to spark application. Each worker node includes an Executor, An Executor runs on the worker node and is responsible for the tasks for the application. By default, the overhead will be larger of either 384 or 10% of spark.executor.memory. A Standard cluster requires a minimum of one Spark worker to run Spark jobs.
client. Each application has its own executors. Hello, I'm new to both Spark and Spark JobServer. To set a higher value for executor memory The role of worker nodes/executors: 1. Search: Airflow Kubernetes Executor Example. One of the ways that you can achieve parallelism in Spark without using Spark data frames is by using the multiprocessing library.
Figure 3.1 shows all the Spark components in the context of a Spark Standalone application. The executor should run closer to the worker nodes because the driver schedules tasks on the cluster. Specifically, to run on a cluster, the SparkContext can connect to several types of cluster managers (either Sparks own standalone cluster manager, Mesos, YARN or Kubernetes), which allocate resources across B.
SparkContext is the entry point to any spark functionality. 172.30.10.10 is the IP address of the host I want to run the jobserver on and it IS reachable from both worker and master nodes (The Spark instances run in Docker containers too, but they are also attached to the host network). 6. The driver is a (daemon|service) wrapper created when you get a spark context (connection) that look after the lifecycle of the Spark job. A Cluster is a group of JVMs (nodes) connected by the network, each of which runs Spark, either in Driver or Worker roles. All nodes run services such as Node Agent and Yarn Node Manager. However, starting the job led to a Connection refused again, this time saying it couldn't connect to 172.30.10.10:nnnn. (Run in Spark 1.6.2) From the logs ->. cluster managerapplication manager The driver: start as its own service (daemon) connect to a cluster manager, get the worker (executor manage them. A cluster node initializationor initscript is a shell script that runs during startup for each cluster node before the Spark driver or worker JVM starts.
In addition to running on the Mesos or YARN cluster managers, Spark also provides a simple standalone deploy mode. I also saw key points to be remembered and how executors are helpful in executing the tasks. The driver node also maintains the SparkContext and interprets all the commands you run from a notebook or a library on the cluster, and runs the Apache Spark master that coordinates with the Spark executors. The default value of the driver node type is the same as the worker node type. They are launched at the beginning of a Spark application and typically run for the entire lifetime of an application. C. Each executor is running a a JVM inside of a worker node. Read from and write the data to the external sources. The central coordinator is called Spark Driver and it communicates with all the Workers. These can be preferably run in the same local area network. 2. When we run any Spark application, a driver program starts, which has the main function and your SparkContext gets initiated here. It listen for and accept incoming connections from itsworker (executorsspark Use 2 worker nodes & Standard workertype for Spark Jobs For PoC purpose, use Glue Python shell for reduced pricing You can create and run an ETL job with a few clicks in the AWS Management Console. Memory Overhead Coefficient Recommended value: .1. Click Advanced Options. D. There are less executors than total number of worker nodes. Spark applications run as independent sets of processes on a cluster, coordinated by the SparkContext object in your main program (called the driver program). We can do that using the --jars property while submitting a new PySpark job: After that, we have to prepare the JDBC connection URL. An executor stays up for the duration of the Spark Application and runs the tasks in multiple threads. Spark driver will run under spark user on the worker node and may not have permissions to write into the location you specify. Executor runs tasks and keeps data in memory or disk storage across them. Here's my attempt at following cluster doc and making this work on Kubernetes:.
spark-submit works on single node only. E. Each executor is a running JVM inside of a cluster manager node. The Driver is one of the nodes in the Cluster. Apache Spark recently released a solution to this problem with the inclusion of the pyspark.pandas library in Spark 3.2. As for your example, Spark doesn't select a Master node. A single node can run multiple executors and executors for an application can span multiple worker nodes. Just add the following line on the nodes you want under /var/lib/dcos/mesos-slave-common (or whatever kind your node is (slave|master|public)) and restart the agent service systemctl restart dcos-mesos-slave.service.
The following diagram shows key Spark objects: the driver program and its associated Spark Context, and the cluster manager and its n worker nodes. If you are downloading from azure storage, there is a simpler way to get access to it from spark. Conclusion. 2. Does this depend on the Cluster manager ? Thread Pools.
Each Worker node consists of one or more Executor(s) who are responsible for running the Task. Spark tries to minimize the memory usage (and we love it for that! For example, setting spark.kubernetes.driver.node.selector.identifier to myIdentifier will result in the driver pod having a node selector with key identifier and value myIdentifier. Now, the Application Master will launch the Driver Program (which will be having the SparkSession/SparkContext) in the Worker node. E. There might be more executors than total nodes or more total nodes than executors. The cluster manager then interacts with each of the worker nodes to understand the number of executors running in each of them. I am executing a TallSkinnySVD program (modified bit to run on big data). then Spark is going to cache its value only in first and second worker nodes. It listen for and accept incoming connections from itsworker (executorsspark
2. We will first create the source table with sample data and then read the data in Spark using JDBC connection We will use the PreparedStatement to update last names of candidates in the candidates table sh script and run following command: /path/to/spark-shell --master spark://:7077 --jars /path/to/mysql-connector-java-5 Open SQuirrel SQL Client and create a new By using the cluster-mode , the resource allocation has the structure shown in the following diagram. I will attempt to provide an illustration of Note the Driver Hostname. While we talk about deployment modes of spark, it specifies where the driver program will be run, basically, it is possible in two ways.At first, either on the worker node inside the cluster, which is also known as Spark cluster mode.. Secondly, on an external client, what we call it as a client spark mode.In this blog, we will learn the whole concept of Apache Spark modes of deployment.
cluster mode is used to run production jobs. This information is stored in spark-defaults.conf on the cluster head nodes. An executor stays up for the duration of the Spark Application and runs the tasks in multiple threads. client mode is majorly used for interactive and debugging purposes. functions import * from pyspark from pyspark pandas user-defined functions Spark High-Level API import pyspark import pyspark. Driver sends work to worker nodes and instructs to pull data from a specified data source and execute transformation and actions on them. A driver of a cluster decides which Worker or Executor node to use for a task after executing a notebook which is attached to the cluster. Is it possible that the Master and the Driver nodes will be the same machine? The library provides a thread abstraction that you can use to create concurrent threads of execution. Open a local terminal. How to Run Apache Spark Application on a cluster. TIP: you can check the environment files that are loaded on the unit file /etc/systemd/system/dcos-mesos-.service A Java application can connect to the Oracle database through JDBC, which is a Java-based API. You will learn more about each component and its function in more detail later in this chapter. Here Spark Driver Programme runs on [labelKey] (none) The two main key roles of drivers are: spark-submit can run the driver within the cluster (e.g., on a YARN worker node), while for others, it can run only on your local machine.
All worker nodes run the Spark Executor service. Setting up Maven's Memory UsageRunning Apache Spark in a Docker environment is not a big deal but running the Spark Worker Nodes on the HDFS Data Nodes is a little bit more sophisticated.
However, by default all of your code will run on the driver node. In yarn-cluster mode, the driver runs in the Application Master. This means that the same process is responsible for both driving the application The executoors will still run in the cluster in worker nodes. The driver is a (daemon|service) wrapper created when you get a spark context (connection) that look after the lifecycle of the Spark job. In cluster mode, the driver runs on one of the worker nodes, and this node shows as a driver on the Spark Web UI of your application. Cluster Manager is Master process in Spark standalone mode. The task scheduler resides in the driver and distributes task among workers. As a best practice, modify the executor memory value accordingly. The executor memory overhead value increases with the executor size (approximately by 6-10%).
What are the roles and responsibilities of worker nodes in the apache spark cluster? Is Worker Node in Spark is same as Slave Node? Worker node refers to node which runs the application code in the cluster. Worker Node is the Slave Node. Master node assign work and worker node actually perform the assigned tasks. Hence we should be careful what we are doing on the driver. The command I gave to run the spark job is. I can't find any firewall (ufw) and iptables rule. Create a standalone Spark cluster v2.3.2 using images from big-data-europe; Clone this repo and create a new Spark Jobserver image with sbt docker; Set master = "spark://spark-master:7077" in docker.conf. In this case, Microsoft.Spark.Worker.net461.win-x64-
In yarn-cluster mode, the driver runs in the Application Master. 1. A single node can run multiple executors and executors for an application can span multiple worker nodes. There is one single worker node that contains the Spark driver and all the executors. B. The Spark Driver runs in a worker node inside the cluster. --> CORRECT C. There is always more than one worker node. D. There are less executors than total number of worker nodes. E. The head node runs additional management services such as Livy, Yarn Resource Manager, Zookeeper, and the Spark driver. Driver.
Before continuing further, I will mention Spark architecture and terminology in brief. Perform the data processing for the application code. I am running spark job using DSE not yarn client/cluster mode, herewith i am including spark submit command for your reference, Apache Drill is a powerful tool for querying a variety of structured and partially structured data stores, including a number of different types of files Until Azure Storage Explorer implements the Selection Statistics feature for ADLS Gen2, here is a code snippet for. Answer (1 of 2): As we know, Spark runs on Master-Slave Architecture. Now from my machine (not inside and docker container), I try to run the following python script but it never completes.
It can be started anywhere by doing ./sbin/start-master.sh, in YARN it would be Resource Manager. Whereas in client mode, the driver runs in the client This working combination of Driver and Workers is known as Spark cluster mode is used to run production jobs.
(JDBC). During a shuffle, the Spark executor first writes its own map outputs locally to disk, and then acts as the server for those files when other executors attempt to fetch them. ), so it won't make any unnecessary memory loads, since it evaluates every statement lazily, i.e. Answer: Check the Microsoft.Spark.Worker version you are using. The executors run throughout the Node Sizes.
You can use init scripts to install packages and libraries not included in the Databricks runtime, modify the JVM system classpath, set system properties and environment variables used by the JVM, or modify Spark
Reply. The driver does not run computations (filter,map, reduce, etc). 3.3.0: spark.kubernetes.executor.node.selector. If deploy-mode is set to client, then Only the Spark Driver will run in client machine or edge node. If deploy-mode is set to cluster (say yarn), the Spark Driver as well executors will run in the yarn cluster in worker nodes. Spark is an engine to distribute workload among worker machines. Each such worker can have N amount of Executor processes running on it. Single-node machine learning workloads that use Spark to load and save data.
In client mode, the Spark driver runs on the host where the spark-submit command is run. A new configuration property spark Airflow Executors Explained Case 2 Hardware 6 Nodes and Each node have 32 Cores, 64 GB The output is intended to be serialized tf Let's see now how Init Containers integrate with Apache Spark driver and executors Let's see now how Init Containers integrate with Apache Spark driver and it won't do any actual work on any transformation, it will wait for an action to happen, which leaves no choice to Spark, than spark-master is the service driver. I am trying to consolidate driver and worker node logs in console or single file and new to spark application. Each worker node includes an Executor, An Executor runs on the worker node and is responsible for the tasks for the application. By default, the overhead will be larger of either 384 or 10% of spark.executor.memory. A Standard cluster requires a minimum of one Spark worker to run Spark jobs.
client. Each application has its own executors. Hello, I'm new to both Spark and Spark JobServer. To set a higher value for executor memory The role of worker nodes/executors: 1. Search: Airflow Kubernetes Executor Example. One of the ways that you can achieve parallelism in Spark without using Spark data frames is by using the multiprocessing library.
Figure 3.1 shows all the Spark components in the context of a Spark Standalone application. The executor should run closer to the worker nodes because the driver schedules tasks on the cluster. Specifically, to run on a cluster, the SparkContext can connect to several types of cluster managers (either Sparks own standalone cluster manager, Mesos, YARN or Kubernetes), which allocate resources across B.
SparkContext is the entry point to any spark functionality. 172.30.10.10 is the IP address of the host I want to run the jobserver on and it IS reachable from both worker and master nodes (The Spark instances run in Docker containers too, but they are also attached to the host network). 6. The driver is a (daemon|service) wrapper created when you get a spark context (connection) that look after the lifecycle of the Spark job. A Cluster is a group of JVMs (nodes) connected by the network, each of which runs Spark, either in Driver or Worker roles. All nodes run services such as Node Agent and Yarn Node Manager. However, starting the job led to a Connection refused again, this time saying it couldn't connect to 172.30.10.10:nnnn. (Run in Spark 1.6.2) From the logs ->. cluster managerapplication manager The driver: start as its own service (daemon) connect to a cluster manager, get the worker (executor manage them. A cluster node initializationor initscript is a shell script that runs during startup for each cluster node before the Spark driver or worker JVM starts.
In addition to running on the Mesos or YARN cluster managers, Spark also provides a simple standalone deploy mode. I also saw key points to be remembered and how executors are helpful in executing the tasks. The driver node also maintains the SparkContext and interprets all the commands you run from a notebook or a library on the cluster, and runs the Apache Spark master that coordinates with the Spark executors. The default value of the driver node type is the same as the worker node type. They are launched at the beginning of a Spark application and typically run for the entire lifetime of an application. C. Each executor is running a a JVM inside of a worker node. Read from and write the data to the external sources. The central coordinator is called Spark Driver and it communicates with all the Workers. These can be preferably run in the same local area network. 2. When we run any Spark application, a driver program starts, which has the main function and your SparkContext gets initiated here. It listen for and accept incoming connections from itsworker (executorsspark Use 2 worker nodes & Standard workertype for Spark Jobs For PoC purpose, use Glue Python shell for reduced pricing You can create and run an ETL job with a few clicks in the AWS Management Console. Memory Overhead Coefficient Recommended value: .1. Click Advanced Options. D. There are less executors than total number of worker nodes. Spark applications run as independent sets of processes on a cluster, coordinated by the SparkContext object in your main program (called the driver program). We can do that using the --jars property while submitting a new PySpark job: After that, we have to prepare the JDBC connection URL. An executor stays up for the duration of the Spark Application and runs the tasks in multiple threads. Spark driver will run under spark user on the worker node and may not have permissions to write into the location you specify. Executor runs tasks and keeps data in memory or disk storage across them. Here's my attempt at following cluster doc and making this work on Kubernetes:.
spark-submit works on single node only. E. Each executor is a running JVM inside of a cluster manager node. The Driver is one of the nodes in the Cluster. Apache Spark recently released a solution to this problem with the inclusion of the pyspark.pandas library in Spark 3.2. As for your example, Spark doesn't select a Master node. A single node can run multiple executors and executors for an application can span multiple worker nodes. Just add the following line on the nodes you want under /var/lib/dcos/mesos-slave-common (or whatever kind your node is (slave|master|public)) and restart the agent service systemctl restart dcos-mesos-slave.service.
The following diagram shows key Spark objects: the driver program and its associated Spark Context, and the cluster manager and its n worker nodes. If you are downloading from azure storage, there is a simpler way to get access to it from spark. Conclusion. 2. Does this depend on the Cluster manager ? Thread Pools.
Each Worker node consists of one or more Executor(s) who are responsible for running the Task. Spark tries to minimize the memory usage (and we love it for that! For example, setting spark.kubernetes.driver.node.selector.identifier to myIdentifier will result in the driver pod having a node selector with key identifier and value myIdentifier. Now, the Application Master will launch the Driver Program (which will be having the SparkSession/SparkContext) in the Worker node. E. There might be more executors than total nodes or more total nodes than executors. The cluster manager then interacts with each of the worker nodes to understand the number of executors running in each of them. I am executing a TallSkinnySVD program (modified bit to run on big data). then Spark is going to cache its value only in first and second worker nodes. It listen for and accept incoming connections from itsworker (executorsspark
2. We will first create the source table with sample data and then read the data in Spark using JDBC connection We will use the PreparedStatement to update last names of candidates in the candidates table sh script and run following command: /path/to/spark-shell --master spark://:7077 --jars /path/to/mysql-connector-java-5 Open SQuirrel SQL Client and create a new By using the cluster-mode , the resource allocation has the structure shown in the following diagram. I will attempt to provide an illustration of Note the Driver Hostname. While we talk about deployment modes of spark, it specifies where the driver program will be run, basically, it is possible in two ways.At first, either on the worker node inside the cluster, which is also known as Spark cluster mode.. Secondly, on an external client, what we call it as a client spark mode.In this blog, we will learn the whole concept of Apache Spark modes of deployment.
cluster mode is used to run production jobs. This information is stored in spark-defaults.conf on the cluster head nodes. An executor stays up for the duration of the Spark Application and runs the tasks in multiple threads. client mode is majorly used for interactive and debugging purposes. functions import * from pyspark from pyspark pandas user-defined functions Spark High-Level API import pyspark import pyspark. Driver sends work to worker nodes and instructs to pull data from a specified data source and execute transformation and actions on them. A driver of a cluster decides which Worker or Executor node to use for a task after executing a notebook which is attached to the cluster. Is it possible that the Master and the Driver nodes will be the same machine? The library provides a thread abstraction that you can use to create concurrent threads of execution. Open a local terminal. How to Run Apache Spark Application on a cluster. TIP: you can check the environment files that are loaded on the unit file /etc/systemd/system/dcos-mesos-