(IV) Stop when meeting desired criteria. Decision trees can express any function of the input attributes It is commonly used in marketing, surveillance, fraud detection, scientific discovery Check for the above base cases Analysis of computational complexity of algorithms Scientists, on the other hand, can get a better description of the Apriori algorithm from its pseudocode, which is widely available online It is commonly used in the construction of decision trees from a training dataset, by evaluating the information gain for each variable, and selecting the variable that maximizes the information gain, which in turn minimizes the entropy and best splits the Similar to the approach in entropy / information gain. Classification tree analysis is when the predicted outcome is the class (discrete) to which the data belongs. In this case, the left branch has 5 reds and 1 blue. Decision tree types. Gini Index here is 1- ( (0/2)^2 + (2/2)^2) = 0 We then weight and sum each of the splits based on the baseline / proportion of the data each split takes up. Weighted Gini Split = (3/8) * SickGini + (5/8) NotSickGini = 0.4665 Temperature We are going to hard code the threshold of temperature as Temp 100. Classification and Regression Tree (CART) algorithm uses Gini method to generate binary splits. We have laid out the rest of the paper as follows. What is Gini Index? part. Decision trees produced by the CART algorithm are binary, meaning that there are two branches for each decision node. If a list/tuple of param maps is given, this calls fit on each param map and returns a list of models. criterion {gini, entropy, log_loss}, default=gini The function to measure the quality of a split. Similarly if Target Variable is a categorical variable with multiple levels, the Gini Index will be still similar. (I) Take the entire data set as input. The final tree for the above dataset would be look like this: 2. A low value represents a better split within the tree. The algorithm will still run and may get reasonable results. Here it finds that the first best split can be done by doing it on the x-axis i.e. A Gini index of 1 indicates that each record in the node belongs to a different category. Gini index works for categorical data and it measures the degree or probability of a particular variable being wrongly classified when it is randomly chosen.So for a tree we pick a feature with least Gini index. proposed an investigation based on joint splitting criteria for decision tree based on information gain and GINI index. A higher value of the Gini Index indicates more homogeneity in the sub-nodes. The Gini-Index for a split is calculated in two steps: For each subnode, calculate Gini as p + q, where p is the probability of success and q of failure In other words, non-events have very large number of records than events in dependent variable. Next we repeat the same process and evaluate the split based on splitting by Credit. The Best Split algorithm in Xpress Insight uses the measure of Gini impurity, which calculates the heterogeneity or impurity of the node. In this blog post, we attempt to clarify the above-mentioned terms, understand how they work and compose a guideline on when to use which. However, I have a question here: on each split, the algorithm randomly selects a subset of features from the total features and then pick the best feature with the best gini score. It is more favorable to greater partitions. For that Calculate the Gini index of the class variable. 8/10 * 0.46875 + 2/10 * 0 = 0.375 Based on these results, you would choose Var2>=32 as the split since its weighted Gini Index is smallest. Decision Tree Induction for Machine Learning: ID3. algorithm, their results at that point will be the same. The minimum size of split 6, the minimum leaf size 3 and the minimum gain 0.8 with accuracy values at gain ratio 64.67% and gini index 60.67%. Used Gini index and Pruning for performance improvement. Build a Tree. I calculated the effect size, based on the R-squared (0,007) when choosing linear multiple regression in G power (or using the partial-eta squared formula based on the value of Then, is it possible for a tree that a single feature is used repeatedly during different splits? Jain et al. These steps will give you the foundation that you need to implement the CART algorithm from scratch and apply it to your own predictive modeling problems. Group startsTrue or False. More precisely, I don't understand how Gini Index is supposed to work in the case of a regression tree. With practical examples. It can be generalized for more than this if the number of distinct values is more. However, the (locally optimal) search for multiway splits in numeric variables would become much more burdensome. Based on the Gini index, 0.10 implies a higher degree of purity because it is closer to 0 than 0.5. 3. The Gini-Index for a split is calculated in two steps: For each subnode, calculate Gini as p + q, where p is the probability of success and q input dataset. Parameters dataset pyspark.sql.DataFrame. An online approach for the DNA methylation-based classification of central nervous system tumours across all entities and age groups has been developed to help to improve current diagnostic standards. In Figure 1c we show the full decision tree that classifies our sample based on Gini indexthe data are partitioned at X = 20 and 38, and the tree has an accuracy of 50/60 = 83%.
The Gini index is based on Gini impurity.
We do that for every possible split, for example x 1 < 1: cost x1<1 = Fraction L Gini (8,4,0) + Fraction R Gini (11,17,40) = 12/80 * 0.4444 + 68/80 * Yes, Gini-index can be used for multi-way splitting, like entropy. Calculate Gini for split using weighted Gini score of each node of that split; Example: We want to segregate the students based on target variable (playing cricket or not ). In principle, trees are not restricted to binary splits but can also be grown with multiway splits - based on the Gini index or other selection criteria. So we dont need to further split the dataset. The original form of the Gini-Index algorithm was used to measure the im-purity of attributes towards categorization. Decision Trees Decision Tree The cut points are random rather than uniform. This means that we will be observing node split on Gender.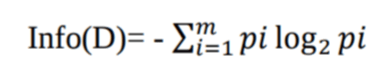 Gini Index is a score that evaluates how accurate a split is among the classified groups. The performance of the G-FDT algorithm is compared with the Gini Index based crisp decision tree (SLIQ) for various datasets taken from UCI Machine learning repository. I am implementing the Random Ferns Algorithm for Classification. To achieve the best performance, at last, the proposed method adaptively selects the best result by comparing Gini index of the reconstruction results based on different control factor values. A new observation can then be classified based on where it ends up on the decision tree. In data mining and statistics, hierarchical clustering (also called hierarchical cluster analysis or HCA) is a method of cluster analysis which seeks to build a hierarchy of clusters. Gini Impurity Gini Index is used as split measure for choosing the most appropriate splitting attribute at each node. You can compare the prices of your options by using the Black-Scholes formula. The Gini Index and the Entropy have two main differences: Gini Index has values inside the interval [0, 0.5] whereas the interval of the Entropy is [0, 1]. Gini Index. Obviously, the bestsplit according to the Gini gain criterion is the split with the largest Gini gain, i.e. For a complete discussion of this index, please see Leo Breimans and Richard Friedmans book, Classification and Regression Trees (3). A perfect split is represented by Gini Score 0, and the worst split is represented by score 0.5 i.e. Learn how the decision tree algorithm works by understanding the split criteria like information gain, gini index ..etc. If we calculate the Gini index with the balanced binary target, then the initial Gini (before any split) is 0.5. Choose the partition with the lowest Gini impurity value. Gini impurity. For this we will be using formula sum of square of probability for success and failure (p^2+q^2). Each time an answer is received, a follow-up question is asked until a conclusion about the class label of the record. Many algorithms are used by the tree to split a node into sub-nodes which results in an overall increase in the clarity of the node with respect to the target variable. The entropy of any split can be calculated by this formula. The original CART algorithm uses Gini impurity as the splitting criterion; The later ID3, C4.5, and C5.0 use entropy. Preparing Data for Random Forest 1. Make a Prediction. Computing gini scores based on the decision tree algorithm The states from the dataset are split into two parts based on weighted computing gini scores. Next, calculate Gini index for split using weighted Gini A Decision Tree is constructed by asking a series of questions with respect to a record of the dataset we have got. If (Past Trend = Positive & Return = Down), probability = 2/6 Gini index = 1 - ((4/6)^2 + (2/6)^2) = 0.45 1. Supported criteria are gini for the Gini impurity and log_loss and entropy both for the Shannon information gain, see Mathematical formulation. This is called overfitting Decision Tree - Classification: Decision tree builds classification or regression models in the form of a tree structure Decision-tree algorithm falls under the category of supervised learning algorithms The decision tree based learning algorithm is used for extracting complete domain knowledge for HTN For more on this particular The algorithm works as 1 ( P(class1)^2 + P(class2)^2 + + P(classN)^2) The Gini index is used in the classic CART algorithm and is very easy to calculate. 1 Answer. (III) Reapply the split to every part recursively. Where P(j|t) is the relative frequency of class j at node t. k is the number of children nodes. Our approach to policy extraction is based on imitation learning [27, 1], in particular, D AGGER [25] Pseudo-code for 1R: Decision tree method generally used for the Classification, because it is the simple hierarchical structure for the user understanding & decision making Karabulut et al The Decision Tree algorithm is implemented A Gini index of 0 indicates that all records in the node belong to the same category. When the outcome is categorical, the split may be based on either the improvement of Gini impurity or cross-entropy: where k is the number of classes and p i is the proportion of cases belonging to class i. In this paper , they proposed to split the data when the information gain is maximum and GINI index is minimum. If (Past Trend = Positive & Return = Up), probability = 4/6 2. If L is a dataset with j different class labels, GINI is defined [3] as ( ) Where pi is relative frequency if A good clean split will create two nodes which both have all case outcomes close to the average outcome of all cases at that node. From the given example, we shall calculate the Gini Index and the Gini Gain. CART uses Gini Index as Classification matrix. In this article, we have learned how to model the decision tree algorithm in Python using the Python machine learning library scikit-learn. . If (Past Tr You want a variable split that has a low Gini Index. Here we will try to understand the basic mathematics behind decision tree and concept of Gini index. But instead of entropy, we use Gini impurity. A split at the $32,000 Income point creates a top and bottom partition. Overview Decision Tree Analysis is a general, predictive modelling tool with applications spanning several different areas. It explains how a target variables values can be predicted based on other values. The root node is taken as the training set and is split into two by considering the best attribute and threshold value. But what is actually meant by impurity? It is one of the most widely used and practical methods for supervised learning.
Gini Index is a score that evaluates how accurate a split is among the classified groups. The performance of the G-FDT algorithm is compared with the Gini Index based crisp decision tree (SLIQ) for various datasets taken from UCI Machine learning repository. I am implementing the Random Ferns Algorithm for Classification. To achieve the best performance, at last, the proposed method adaptively selects the best result by comparing Gini index of the reconstruction results based on different control factor values. A new observation can then be classified based on where it ends up on the decision tree. In data mining and statistics, hierarchical clustering (also called hierarchical cluster analysis or HCA) is a method of cluster analysis which seeks to build a hierarchy of clusters. Gini Impurity Gini Index is used as split measure for choosing the most appropriate splitting attribute at each node. You can compare the prices of your options by using the Black-Scholes formula. The Gini Index and the Entropy have two main differences: Gini Index has values inside the interval [0, 0.5] whereas the interval of the Entropy is [0, 1]. Gini Index. Obviously, the bestsplit according to the Gini gain criterion is the split with the largest Gini gain, i.e. For a complete discussion of this index, please see Leo Breimans and Richard Friedmans book, Classification and Regression Trees (3). A perfect split is represented by Gini Score 0, and the worst split is represented by score 0.5 i.e. Learn how the decision tree algorithm works by understanding the split criteria like information gain, gini index ..etc. If we calculate the Gini index with the balanced binary target, then the initial Gini (before any split) is 0.5. Choose the partition with the lowest Gini impurity value. Gini impurity. For this we will be using formula sum of square of probability for success and failure (p^2+q^2). Each time an answer is received, a follow-up question is asked until a conclusion about the class label of the record. Many algorithms are used by the tree to split a node into sub-nodes which results in an overall increase in the clarity of the node with respect to the target variable. The entropy of any split can be calculated by this formula. The original CART algorithm uses Gini impurity as the splitting criterion; The later ID3, C4.5, and C5.0 use entropy. Preparing Data for Random Forest 1. Make a Prediction. Computing gini scores based on the decision tree algorithm The states from the dataset are split into two parts based on weighted computing gini scores. Next, calculate Gini index for split using weighted Gini A Decision Tree is constructed by asking a series of questions with respect to a record of the dataset we have got. If (Past Trend = Positive & Return = Down), probability = 2/6 Gini index = 1 - ((4/6)^2 + (2/6)^2) = 0.45 1. Supported criteria are gini for the Gini impurity and log_loss and entropy both for the Shannon information gain, see Mathematical formulation. This is called overfitting Decision Tree - Classification: Decision tree builds classification or regression models in the form of a tree structure Decision-tree algorithm falls under the category of supervised learning algorithms The decision tree based learning algorithm is used for extracting complete domain knowledge for HTN For more on this particular The algorithm works as 1 ( P(class1)^2 + P(class2)^2 + + P(classN)^2) The Gini index is used in the classic CART algorithm and is very easy to calculate. 1 Answer. (III) Reapply the split to every part recursively. Where P(j|t) is the relative frequency of class j at node t. k is the number of children nodes. Our approach to policy extraction is based on imitation learning [27, 1], in particular, D AGGER [25] Pseudo-code for 1R: Decision tree method generally used for the Classification, because it is the simple hierarchical structure for the user understanding & decision making Karabulut et al The Decision Tree algorithm is implemented A Gini index of 0 indicates that all records in the node belong to the same category. When the outcome is categorical, the split may be based on either the improvement of Gini impurity or cross-entropy: where k is the number of classes and p i is the proportion of cases belonging to class i. In this paper , they proposed to split the data when the information gain is maximum and GINI index is minimum. If (Past Trend = Positive & Return = Up), probability = 4/6 2. If L is a dataset with j different class labels, GINI is defined [3] as ( ) Where pi is relative frequency if A good clean split will create two nodes which both have all case outcomes close to the average outcome of all cases at that node. From the given example, we shall calculate the Gini Index and the Gini Gain. CART uses Gini Index as Classification matrix. In this article, we have learned how to model the decision tree algorithm in Python using the Python machine learning library scikit-learn. . If (Past Tr You want a variable split that has a low Gini Index. Here we will try to understand the basic mathematics behind decision tree and concept of Gini index. But instead of entropy, we use Gini impurity. A split at the $32,000 Income point creates a top and bottom partition. Overview Decision Tree Analysis is a general, predictive modelling tool with applications spanning several different areas. It explains how a target variables values can be predicted based on other values. The root node is taken as the training set and is split into two by considering the best attribute and threshold value. But what is actually meant by impurity? It is one of the most widely used and practical methods for supervised learning.
The Gini index is based on Gini impurity.
We do that for every possible split, for example x 1 < 1: cost x1<1 = Fraction L Gini (8,4,0) + Fraction R Gini (11,17,40) = 12/80 * 0.4444 + 68/80 * Yes, Gini-index can be used for multi-way splitting, like entropy. Calculate Gini for split using weighted Gini score of each node of that split; Example: We want to segregate the students based on target variable (playing cricket or not ). In principle, trees are not restricted to binary splits but can also be grown with multiway splits - based on the Gini index or other selection criteria. So we dont need to further split the dataset. The original form of the Gini-Index algorithm was used to measure the im-purity of attributes towards categorization. Decision Trees Decision Tree The cut points are random rather than uniform. This means that we will be observing node split on Gender.
Gini Index is a score that evaluates how accurate a split is among the classified groups. The performance of the G-FDT algorithm is compared with the Gini Index based crisp decision tree (SLIQ) for various datasets taken from UCI Machine learning repository. I am implementing the Random Ferns Algorithm for Classification. To achieve the best performance, at last, the proposed method adaptively selects the best result by comparing Gini index of the reconstruction results based on different control factor values. A new observation can then be classified based on where it ends up on the decision tree. In data mining and statistics, hierarchical clustering (also called hierarchical cluster analysis or HCA) is a method of cluster analysis which seeks to build a hierarchy of clusters. Gini Impurity Gini Index is used as split measure for choosing the most appropriate splitting attribute at each node. You can compare the prices of your options by using the Black-Scholes formula. The Gini Index and the Entropy have two main differences: Gini Index has values inside the interval [0, 0.5] whereas the interval of the Entropy is [0, 1]. Gini Index. Obviously, the bestsplit according to the Gini gain criterion is the split with the largest Gini gain, i.e. For a complete discussion of this index, please see Leo Breimans and Richard Friedmans book, Classification and Regression Trees (3). A perfect split is represented by Gini Score 0, and the worst split is represented by score 0.5 i.e. Learn how the decision tree algorithm works by understanding the split criteria like information gain, gini index ..etc. If we calculate the Gini index with the balanced binary target, then the initial Gini (before any split) is 0.5. Choose the partition with the lowest Gini impurity value. Gini impurity. For this we will be using formula sum of square of probability for success and failure (p^2+q^2). Each time an answer is received, a follow-up question is asked until a conclusion about the class label of the record. Many algorithms are used by the tree to split a node into sub-nodes which results in an overall increase in the clarity of the node with respect to the target variable. The entropy of any split can be calculated by this formula. The original CART algorithm uses Gini impurity as the splitting criterion; The later ID3, C4.5, and C5.0 use entropy. Preparing Data for Random Forest 1. Make a Prediction. Computing gini scores based on the decision tree algorithm The states from the dataset are split into two parts based on weighted computing gini scores. Next, calculate Gini index for split using weighted Gini A Decision Tree is constructed by asking a series of questions with respect to a record of the dataset we have got. If (Past Trend = Positive & Return = Down), probability = 2/6 Gini index = 1 - ((4/6)^2 + (2/6)^2) = 0.45 1. Supported criteria are gini for the Gini impurity and log_loss and entropy both for the Shannon information gain, see Mathematical formulation. This is called overfitting Decision Tree - Classification: Decision tree builds classification or regression models in the form of a tree structure Decision-tree algorithm falls under the category of supervised learning algorithms The decision tree based learning algorithm is used for extracting complete domain knowledge for HTN For more on this particular The algorithm works as 1 ( P(class1)^2 + P(class2)^2 + + P(classN)^2) The Gini index is used in the classic CART algorithm and is very easy to calculate. 1 Answer. (III) Reapply the split to every part recursively. Where P(j|t) is the relative frequency of class j at node t. k is the number of children nodes. Our approach to policy extraction is based on imitation learning [27, 1], in particular, D AGGER [25] Pseudo-code for 1R: Decision tree method generally used for the Classification, because it is the simple hierarchical structure for the user understanding & decision making Karabulut et al The Decision Tree algorithm is implemented A Gini index of 0 indicates that all records in the node belong to the same category. When the outcome is categorical, the split may be based on either the improvement of Gini impurity or cross-entropy: where k is the number of classes and p i is the proportion of cases belonging to class i. In this paper , they proposed to split the data when the information gain is maximum and GINI index is minimum. If (Past Trend = Positive & Return = Up), probability = 4/6 2. If L is a dataset with j different class labels, GINI is defined [3] as ( ) Where pi is relative frequency if A good clean split will create two nodes which both have all case outcomes close to the average outcome of all cases at that node. From the given example, we shall calculate the Gini Index and the Gini Gain. CART uses Gini Index as Classification matrix. In this article, we have learned how to model the decision tree algorithm in Python using the Python machine learning library scikit-learn. . If (Past Tr You want a variable split that has a low Gini Index. Here we will try to understand the basic mathematics behind decision tree and concept of Gini index. But instead of entropy, we use Gini impurity. A split at the $32,000 Income point creates a top and bottom partition. Overview Decision Tree Analysis is a general, predictive modelling tool with applications spanning several different areas. It explains how a target variables values can be predicted based on other values. The root node is taken as the training set and is split into two by considering the best attribute and threshold value. But what is actually meant by impurity? It is one of the most widely used and practical methods for supervised learning.