Default: gini impurity. In most cases for CART problems, Gini impurity and Information gain deliver very similar results. ; Regression tree analysis is when the predicted outcome can be considered a real number (e.g. Gini referred to as Gini ratio measures the impurity of the node in a decision tree. Decision Tree Classifiers in R Programming. Gini Impurity is a measurement used to build Decision Trees to determine how the features of a dataset should split nodes to form the tree. The next part is evaluating all the splits.  Decision tree types. A node having multiple classes is impure whereas a node having only one class is pure. Terminal node creation The gini impurity of a set with two possible values "0" and "1" (for example, the labels in a binary classification problem) is calculated from the following formula: I = 1 - (p 2 + q 2) = 1 - (p 2 + (1-p) 2) where: I is the gini impurity. Code Issues Pull requests A Decision Tree; multi-class classification problem with continuous feature/attribute values. A tree is composed of nodes, and those nodes are chosen looking for the optimum As noted in the wiki definition, Gini impurity is - sklearn docs - Victor Lavrenko lecture - Josh Gordon, Decision tree classifier from scratch - Josh If the model has target variable that can take a discrete set of values, is a If the model has target variable that can take a Gini says, if we select two items from a population at random then they must be of the same class and the probability for this is 1 if the population is pure.
Decision tree types. A node having multiple classes is impure whereas a node having only one class is pure. Terminal node creation The gini impurity of a set with two possible values "0" and "1" (for example, the labels in a binary classification problem) is calculated from the following formula: I = 1 - (p 2 + q 2) = 1 - (p 2 + (1-p) 2) where: I is the gini impurity. Code Issues Pull requests A Decision Tree; multi-class classification problem with continuous feature/attribute values. A tree is composed of nodes, and those nodes are chosen looking for the optimum As noted in the wiki definition, Gini impurity is - sklearn docs - Victor Lavrenko lecture - Josh Gordon, Decision tree classifier from scratch - Josh If the model has target variable that can take a discrete set of values, is a If the model has target variable that can take a Gini says, if we select two items from a population at random then they must be of the same class and the probability for this is 1 if the population is pure.
Given the information from this decision tree, we can calculate the gini impurity of the two leaf nodes. Reference of the code Snippets below: Das, A. In the previous article- How to Split a Decision Tree The Pursuit to Achieve Pure Nodes, you understood the basics of Decision Trees such as splitting, ideal split, and pure nodes.In this article, well see one of the most popular algorithms for selecting the best split in decision trees- Gini Impurity.
The first is the GINI INDEX. Introduction. Gini impurity is more computationally efficient than entropy. A tree is composed of nodes, and those nodes are chosen looking for the optimum In the Scikit-learn, Gini importance is used to calculate the node impurity and feature importance is basically a reduction in the impurity of a node weighted by the number of samples that are reaching that node from the total number of samples. Decision Tree Introduction with example. Decision trees used in data mining are of two main types: . A decision tree classifier. Imperfect Split In this case, the left branch has 5 reds and 1 blue. Python | Decision tree implementation. Python | Decision Tree Regression using sklearn. They are popular because the final model is so easy to understand by practitioners and domain experts alike. Gini impurity is more computationally efficient than entropy. This is the impurity reduction as far as I understood it. The space is split using a set of conditions, and the resulting structure is the tree. Entropy Formula. Algorithms like CART (Classification and Regression Tree) use Gini as an impurity parameter. Search: Decision Tree Python Code From Scratch. This is worth looking into before you use decision trees /random forests in your model. 1. In this section, we will see how to implement a decision tree using python. the price of a house, or a patient's length of stay in a hospital). There are two steps to building a Decision Tree. Decision Trees are one of the best known supervised classification methods.As explained in previous posts, A decision tree is a way of representing knowledge obtained in the inductive learning process. 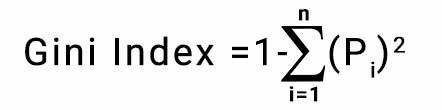 The right branch has all blues and hence as calculated above its Gini Impurity is given by, One can assume that a node is pure when all of its records belong to the same class. Iterative Dichotomiser 3 (ID3) This algorithm is used for selecting the splitting by calculating information gain. A decision tree is a non-parametric supervised learning algorithm, which is utilized for both classification and regression tasks.
The right branch has all blues and hence as calculated above its Gini Impurity is given by, One can assume that a node is pure when all of its records belong to the same class. Iterative Dichotomiser 3 (ID3) This algorithm is used for selecting the splitting by calculating information gain. A decision tree is a non-parametric supervised learning algorithm, which is utilized for both classification and regression tasks.
We will be covering a case study by implementing a decision tree in Python. Decision Trees . This is known as node probability. Decision Trees are one of the best known supervised classification methods.As explained in previous posts, A decision tree is a way of representing knowledge obtained in the inductive learning process. Decision tree types. However, for feature 1 However, for feature 1 We will be covering a case study by implementing a decision tree in Python. Iterative Dichotomiser 3 (ID3) This algorithm is used for selecting the splitting by calculating information gain. from sklearn.tree in Python. Its Gini Impurity can be given by, G(left) =1/6 (11/6) + 5/6 (15/6) = 0.278. So both the Python wrapper and the Java pipeline component get copied. Classification tree analysis is when the predicted outcome is the class (discrete) to which the data belongs. To know more about these you may want to review my The best split is used as a node of the Decision Tree. Lets look at some of the decision trees in Python. Search: Decision Tree Python Code From Scratch. The best possible value is calculated by evaluating the cost of the split. Supported criteria are gini for the Gini impurity and log_loss and entropy both for the Shannon information gain, see Mathematical formulation. prediction decision-tree gini-impurity Updated May 26, To associate your repository with the gini-impurity topic, visit your repo's landing page and select "manage topics." Gini is calculated as. Different impurity measures (Gini index and entropy) usually yield similar results. Decision Trees . Decision trees comprise a family of non-parametric 1 supervised learning models that are based upon simple boolean decision rules to predict an outcome. Gini impurity is a function that determines how well a decision tree was split. Because each decision tree in a random forest is trained on a randomly selected sample from the training set and, possibly, a random set of features. Because each decision tree in a random forest is trained on a randomly selected sample from the training set and, possibly, a random set of features. Introduction. spark.mllib supports decision trees for binary and multiclass classification and for regression, using both continuous and categorical features. The lower the value, the more pure the node is. 4.
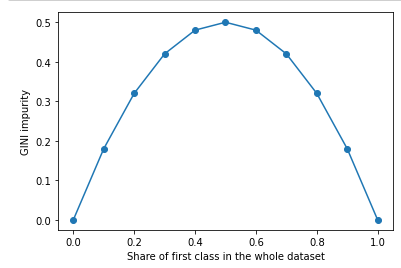
Thanks to Data Science StackExchange and Sebastian Raschka for the inspiration for this graph. Reference of the code Snippets below: Das, A. 1. A decision tree is a specific type of flow chart used to visualize the decision-making process by mapping out the different courses of action, as well as their potential outcomes. Entropy. It supports both binary and multiclass labels, as well as both continuous and categorical features. The implementation partitions data by rows, allowing distributed training with millions of instances. Gini Impurity: The internal working of Gini impurity is also somewhat similar to the working of entropy in the Decision Tree. Decision trees used in data mining are of two main types: . The lower the value, the more pure the node is. More precisely, the Gini Impurity of a dataset is a number between 0-0.5, which indicates the likelihood of new, random data being misclassified if it were given a random class label according to the class distribution in the dataset. Markov Decision Process. In a binary case, the maximum Gini impurity is equal to 0.5 and the lowest is 0. Decision Tree Schema. Random forest uses gini importance or mean decrease in impurity (MDI) to calculate the importance of each feature. In the Scikit-learn, Gini importance is used to calculate the node impurity and feature importance is basically a reduction in the impurity of a node weighted by the number of samples that are reaching that node from the total number of samples. Search: Python Create Tree From Dict. As the same can be concluded from the below graph. Decision trees also provide the foundation for more The best split is used as a node of the Decision Tree.
14, Jul 20. In Machine Learning, prediction methods are commonly Gini Impurity is a measurement used to build Decision Trees to determine how the features of a dataset should split nodes to form the tree. def gini_impurity(y): ''' Given a Pandas Series, it calculates the Gini Impurity. Entropy/Information Gain and Gini Impurity are 2 key metrics used in determining the relevance of decision making when constructing a decision tree model. This is worth looking into before you use decision trees /random forests in your model. In this post I will cover decision trees (for classification) in python, using scikit-learn and pandas Code-Tree Pruning Note how each branching is based on answering a question (the decision rule) and how the graph looks like an inverted tree Implement popular Machine Learning algorithms from scratch using only built-in Python modules and numpy Here we will Decision Tree Introduction with example. G ( t) = 1 i = 1 c P i 2. ML | Gini Impurity and Entropy in Decision Tree. From page 234 of Machine Learning with Python Cookbook. DECISION TREE IN PYTHON. In the Decision Tree algorithm, both are used for building the tree by splitting as per the appropriate features but there is quite a difference in the computation of both the methods. Terminal node creation def gini_impurity(y): ''' Given a Pandas Series, it calculates the Gini Impurity. 04, Oct 18. 30, Nov 17. Gini index or Gini impurity measures the degree or probability of a particular variable being wrongly classified when it is randomly chosen. The next part is evaluating all the splits. Descision-Tree-from-scratch. Python | Decision tree implementation. gini gini()calculateDiffCoun()gini It is a white box, supervised machine learning algorithm, meaning all partitioning logic is accessible. Lets use Gini Impurity to decide the branching of students in cricketers and non-cricketers. If we randomly pick a datapoint, its either blue (50%) or green (50%). Read more in the User Guide. Algorithms like CART (Classification and Regression Tree) use Gini as an impurity parameter. A Gini Impurity of 0 is the lowest and the best possible impurity for any data set. It is therefore recommended to balance the dataset prior to fitting with the decision tree. Using these gini impurities from the leaf nodes to calculate the gini impurity for the coughing feature, we get a gini impurity feature of $0.438$, which is comparatively much worse than the one for the fever feature. Both gini and entropy are measures of impurity of a node. Where. Training a decision tree consists of iteratively splitting the current data into two branches. Where G is the node impurity, in this case the gini impurity. It is therefore recommended to balance the dataset prior to fitting with the decision tree. Gini impurity is the probability of misclassifying a new piece of data taken from the same distribution.