and get access to the augmented documentation experience. As explained here, the initial layers learn very general features and as we go higher up the network, the layers tend to learn patterns more specific to the task it is being trained on. 2.1 Architecture section, we can see that the authors stated that, "The only preprocessing we do is subtracting the mean RGB value, computed on the training set, from each pixel.".
Unfreeze the 10 last layers of the convolutional base. Note a very common pitfall here you can just pass the name of the loss as a string to Keras, but by default Keras will assume that you have already applied a softmax to your outputs. Note that we are using a Dense layer with one node as our output. Example transformations: Pixel color jitter, rotation, shearing, random cropping, horizontal flipping, stretching, lens correction. In this program, Ill demonstrate both transfer learning and fine-tuning. We then iterate over each of the layers in vgg16_model, except for the last layer, and add each layer to the new This linkis an affiliate link, meaning I get a commission if you decide to make a purchase through it, at no cost to you. For multi-class classification, we would use the "sparse_categorical_crossentropy" loss.
Training and watching the loss go down is all very nice, but what if we want to actually get outputs from the trained model, either to compute some metrics, or to use the model in production? Great tutorial, but I have one question. # by the total number of epochs. 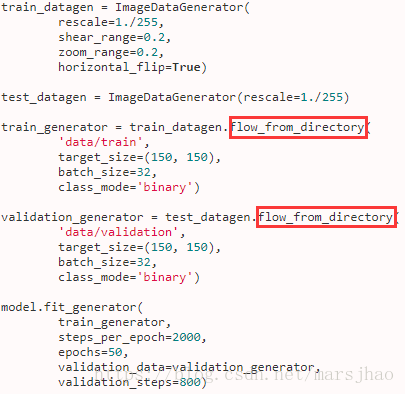
or shoes? Stay tuned for the next post in the series: If you have any questions contact me at greg.ht.chu@gmail.comor message me on LinkedIn! It concludes by encouraging you to train the model, which is exactly what we are going to do now. that optimizer with default values for all parameters, including learning rate. Under the In the literature, you will sometimes see this referred to as decaying or annealing As an example, I trained a model on the dogs-vs-cats dataset using 24000 images for training and 1000 images for validation for 2 epochs. or different types of lung disease in X-ray images? We kept the validation set same as the previous post i.e. Then we tried to fine-tune the network by following these steps: This allowed us to improve the accuracy of the model up to 96%. # not the original Hugging Face Dataset, so its len() is already num_samples // batch_size. I hope you find this useful. Hey, we're Chris and Mandy, the creators of deeplizard! This processing is what is causing the underlying color data to look distorted. Next, we add our new output layer, consisting of only 2 nodes that correspond to cat and dog.
Now what we can do to further improvethe accuracy of the model is to use fine-tuning. In this episode, we'll demonstrate how to fine-tune a pre-trained model to classify images as cats and dogs. The pre-trained model we'll be working with to classify images of cats and dogs is called VGG16, which is the model that won the 2014 00:16 VGG16 and ImageNet We can plot the training accuracies and loss using the history object. Why is the size of fully connected layer chosen as 1024? This is the preprocessing that was used on the original training data, and therefore, this is the way we need to process images before passing them to VGG16 or a fine-tuned VGG16 model. Note that dogs and cats were included in the ImageNet library from which VGG16 was originally trained. After the training is over, we will save the model.
We generally use transfer learning when we have a small dataset, so it isgood practice to apply data augmentation to artificially augment the dataset and thus get better accuracy and reduce overfitting. I hope you enjoyed the tutorial! I get the error: Note, an internet connection is needed to download this model. It has become the norm, not the exception, for researchers and practitioners alike to use transfer learning and fine-tuning, that is, transferring the network weights trained on a previous task like ImageNet to a new task. Record the outputs to a Numpy array, CSV file, or something else. As with the loss, when we pass Keras the name of an optimizer as a string, Keras initializes Note that to use the internal loss youll need to pass your labels as part of the input, not as a separate label, which is the normal way to use labels with Keras models. The figure above and the bullets below describe some general advice for when to choose which approach. You can also directly run the code onGoogle Colab. We will also apply caching, shuffling, batching, and prefetching to speed loading. Razavian et al (2014) showed that by simply using the features extracted using the weights from an ImageNet ILSVRC trained model, they achieved state-of-the-art or near state-of-the-art performance on a large variety of computer vision tasks. we talk about fine tunning the full network, when New dataset is large and similar to the original dataset. Since we're only going to be classifying two categories, cats and dogs, we need to modify this model in order for it to do what we want it to do, which is to Robotics Engineering, Warsaw University of Technology, PhD in HCI, Founder of Concepta.me and Aptum, Computer Science Student, University of Central Lancashire, Software Programmer, King Abdullah University of Science and Technology. DEEPLIZARD COMMUNITY RESOURCES All views expressed on this site are my own and do not represent the opinions of OpenCV.org or any entity whatsoever with which I have been, am now, or will be affiliated. Just to recap, when we train a network from scratch, we encounter the following two limitations : The task of fine-tuning a network is to tweak the parameters of an already trained network so that it adapts to the new task at hand. Feature extraction consists of propagating the input images through the base modeland taking the outputs to train a newclassifier. 5e-5 (0.00005), which is some twenty times lower, is a much better starting point. The object returned has a compute() method we can use to do the metric calculation: The exact results you get may vary, as the random initialization of the model head might change the metrics it achieved. We will use two different data generators for train and validation folders.
Why it is one FCL?? Freezing a layer means that we make its weights non-trainable and thus gradient descent won't update them. Trained the new fully connected layers that was added on top. In later episodes, we'll do more involved fine-tuning and utilize transfer learning to classify completely new data than what was included in the training set. When can we expect the upcoming posts? Here we are getting a much better accuracy of 98%.
Let's plot the learning curves for the accuracy and the loss: We reached an accuracy of87% and thanks to data augmentation, the model is not overfitting the data. If you would like to hone your skills on the Keras API, try to fine-tune a model on the GLUE SST-2 dataset, using the data processing you did in section 2. Theas_supervised=Trueargument will return the data in a tuple (image, label) instead of a dictionary{'image': image, 'label': label}. We will use the VGG model for fine-tuning. Then I apply more regularization techniques to get rid of overfiiting. Here is a short summary recapping what you need: TensorFlow models imported from Transformers are already Keras models. This is because BERT has not been pretrained on classifying pairs of sentences, so the head of the pretrained model has been discarded and a new head suitable for sequence classification has been inserted instead. Shuffling the data is only necessary for the training and the validation set. Here i am confused about What exactly does it mean by fine tuning. Let's first import the required packages: Now we can use tensorflow_datasets to load the dataset: The original dataset contains only a training set. More often than not, however, the categories we are interested in predicting are not in that list. 00:00 Welcome to DEEPLIZARD - Go to deeplizard.com for learning resources
Thus, for fine-tuning, we want to keep the initial layers intact ( or freeze them ) and retrain the later layers for our task. The fine-tuned model will not classify images as one of the 1000 categories for which it was trained on, but instead Huge computing power required Even if we have a lot of data, training generally requires multiple iterations and it takes a toll on the computing resources. Till now, we have created the model and set up the data for training. Please also note that fine tuning is only possible if you perform feature extraction with the second method mentioned above. 2021 Copyright: dontrepeatyourself. Checkout the github for the full program. Note that Transformers models have a special ability that most Keras models dont - they can automatically use an appropriate loss which they compute internally. PolynomialDecay despite the name, with default settings it simply linearly decays the learning rate from the initial And it does astoundingly well! VIDEO SECTIONS Let's use the model to make some predictions on a batch of images: If you want to learn more about transfer learning and fine-tuning I recommend the following resources. Well use an Amazon EC2 g2.2xlarge instance for training.
Only a doubt: you use rescale in ImageDataGenerator.
We obtained an accuracy of 90% with the transfer learning approach discussed in our previous article. This will start the fine-tuning process (which should take a couple of minutes on a GPU) and report training loss as it goes, plus the validation loss at the end of each epoch. 04:17 Building a Fine-tuned Model That was the uncased model while we are currently using the cased model, which explains the better result. Here we have unfrozen the 10 last layers for fine-tuning but you can try freezing/unfreezing more layers to see what performance you get. The original trained VGG16 model, along with its saved weights and other parameters, is now downloaded onto our machine. The primary cause later episodes using the MobileNet model. Let's create a Sequential model with some layers that willapplyrandom transformationsto the training set: Let's see what an image will look like after applying these transformations: Convolutional neural networks are made of two parts: the first part consists ofa stack of alteredconvolutionaland poolinglayers, which is generally called a convolutional base, and the second part consists ofa densely connected classifier added on top of the convolutional base. First, we will load a VGG model without the top layer ( which consists of fully connected layers ).
2. Thank you for your support! This website is made possible by displaying online advertisements to our visitors. Here is a short introduction to Keras. VGG16 is much more complex and sophisticated and has many more layers than our previous model. You can choose to use a larger dataset if you have a GPU as the training will take much longer if you do it on a CPU for a large dataset. We hate SPAM and promise to keep your email address safe. I was doing a self-study on AI, when I came across with Opencv summer course. A powerful and common tool for increasing the dataset size and model generalizability is data augmentation. By using the with_info=Trueargument we get some information about the dataset. It is important to only try fine-tuning after training the densely connected classifier that has been added on top of the convolutional base because otherwise the updates of the weights will be too large and this will destroy the features learned by thelayersbeing fine-tuned. This course is available for FREE only till 22. Training the last 3 convolutional layers We got 9 errors out of 150. Thank you for all these awesome tutorials. This will require less training data and training will be much faster. We use the flag include_top=False to leave out the weights of the last fully connected layer since that is specific to the ImageNet competition, from which the weights were previously trained. This will return the logits from the output head of the model, one per class. Thats it! though, we need to tell it how long training is going to be. Deep Learning Fundamentals course. Let us see the loss and accuracy curves using visualize_results(history) function: Also, let us visually see the errors that we got. Second, the part that is being trained is not trained from scratch. Then we add on a fully-connected Dense layer of size 1024, and a softmax function on the output to squeeze the values between [0,1]. All rights reserved. This is set by preprocessing_function = preprocess_input where preprocess_input is from the keras.applications.inception_v3 module. Next, we'll iterate over each of the layers in our new Sequential model and set them to be non-trainable. If you try the above code, it certainly runs, but youll find that the loss declines only slowly or sporadically. For sequence classification, however, a standard Keras loss function works fine, so thats what well use here. Let's first check out a batch of training data using the plotting function we brought in previously. In the ImageNet competition, multiple teams compete to build a model that best classifies images from the ImageNet library. It summarize the important computer vision aspects you should know which are now eclipsed by deep-learning-only courses. Did you know you that deeplizard content is regularly updated and maintained? a couple episodes back when we began our work on CNNs. Is there any conceptual reason?. For now, we're going to go through a process to convert the Functional model to a Sequential model, so that it will be easier for us to work with given our current knowledge. , https://deeplizard.com/learn/video/RznKVRTFkBY, https://deeplizard.com/learn/video/v5cngxo4mIg, https://deeplizard.com/learn/video/nyjbcRQ-uQ8, https://deeplizard.com/learn/video/d11chG7Z-xk, https://deeplizard.com/learn/video/ZpfCK_uHL9Y, https://youtube.com/channel/UCSZXFhRIx6b0dFX3xS8L1yQ, Keras with TensorFlow Prerequisites - Getting Started With Neural Networks, TensorFlow and Keras GPU Support - CUDA GPU Setup, Keras with TensorFlow - Data Processing for Neural Network Training, Create an Artificial Neural Network with TensorFlow's Keras API, Train an Artificial Neural Network with TensorFlow's Keras API, Build a Validation Set With TensorFlow's Keras API, Neural Network Predictions with TensorFlow's Keras API, Create a Confusion Matrix for Neural Network Predictions, Save and Load a Model with TensorFlow's Keras API, Image Preparation for Convolutional Neural Networks with TensorFlow's Keras API, Code Update for CNN Training with TensorFlow's Keras API, Build and Train a Convolutional Neural Network with TensorFlow's Keras API, Convolutional Neural Network Predictions with TensorFlow's Keras API, Data Augmentation with TensorFlow's Keras API, Build a Fine-Tuned Neural Network with TensorFlow's Keras API, Train a Fine-Tuned Neural Network with TensorFlow's Keras API, Predict with a Fine-Tuned Neural Network with TensorFlow's Keras API, MobileNet Image Classification with TensorFlow's Keras API, Process Images for Fine-Tuned MobileNet with TensorFlow's Keras API, Fine-Tuning MobileNet on Custom Data Set with TensorFlow's Keras API, Deep Learning with TensorFlow - Course Conclusion. Hi.. The include_top=Falsemeans that we load the model without the "second part" of the model; the densely connected classifier. This concludes the introduction to fine-tuning using the Keras API.
A place to explore, learn, and build using open source deep learning tools, DeterminedA Batteries-Included Deep Learning Training Platform, Using Machine Learning to replace Joo Flix, TensorFlow 2.0: tf.function and AutoGraph, Visualizing Deep Learning Model Architecture, Answering Multiple-Choice Questions from Gaokao English Exam, Generative Adversarial Networks (GANS) - A Practical Implementation, Handwritten Text Recognition using Convolutional Neural Networks (CNN), Real-Time Face Detection with Dual Shot Face Detector (DSFD), train_generator = train_datagen.flow_from_directory(, validation_generator = test_datagen.flow_from_directory(. is the learning rate. Keras BlogDeep Learning with Python Github Repository, Filed Under: Deep Learning, how-to, Tutorial. Thanks for keeping your article so simple but of high utility. Note, however, that the model.fit() command will run very slowly on a CPU. If so don't forget tosubscribe to the mailinglist to be notified of future posts. it will only work to classify images as either cats or dogs. Is there a way to get the confusion matrix or maybe the TP,TN, FP and FN in your code above? By using weights="imagenet", we are telling Keras to load the model withweights trained on the ImageNet dataset. First, lets reload the model, to reset the changes to the weights from the training run we just did, and then we can compile it with the new optimizer: If you want to automatically upload your model to the Hub during training, you can pass along a PushToHubCallback in the model.fit() method. We have designed this FREE crash course in collaboration with OpenCV.org to help you take your first steps into the fascinating world of Artificial Intelligence and Computer Vision. We get an improvement of 9%. To understand In this tutorial, we will learn how to fine-tune a pre-trained model for a different task than it was originally trained for. I mean do we use the weights of per-trained model for fine tunning. Well use Kaggles Dogs vs Cats dataset as our example, and setup our data with a training directory and a validation directory in this manner: Lets start by preparing our data generators: Recall from our previous blog post on image recognition the importance of the preprocessing step. Basically, there are two ways to use feature extraction: Or we can use feature extraction like this: Fine-tuning consists of unfreezing the top layers of thebase model and retrain the networkwith alow learning rate. We will use the VGG19 model pre-trained on ImageNet as our base model. The keyword "engineering oriented" surprised me nicely. For example, the ImageNet ILSVRC model was trained on 1.2 million images over the period of 23 weeks across multiple GPUs. from keras.preprocessing.image import ImageDataGenerator, load_img, Your email address will not be published. Required fields are marked *. Freezing all layers and learning a classifier on top of it similar to transfer learning. Tofreeze alllayers of a model, we can set its trainable attribute to False: Now let's add a simple fullyconnected classifier using the Sequential model: We first add the data_augmentation model, then a Rescaling layer is added to standardize the values to [0, 1] range, followed by the convolutional base, and finally, we add a new fully connected classifier. Try doing your own experiments and post your findings in the comments section. Many models, however, output the values right before the softmax is applied, which are also known as the logits.
The course is divided into weekly lessons, those are crystal clear for different phase learners. We can load the metrics associated with the MRPC dataset as easily as we loaded the dataset, this time with the load_metric() function.
Next, well instantiate the InceptionV3 network from the keras.applications module. base_model = InceptionV3(weights='imagenet', include_top=False). Now that we have set the trainable parameters of our base network, we would like to add a classifier on top of the convolutional base. We'll import this VGG16 model and then fine-tune it using Keras. When doing this I should use the learned weigths after those epochs (who leaded to overfitting) as starting point or I should do all the transfer learning + finetunning process again from begining (Imagenet weights)? The code examples below assume you have already executed the examples in the previous section. Now, we have replicated the entire vgg16_model (excluding the output layer) to a new Sequential model, which we've just given the name model. In order to not lose the representationslearned by the convolutional base (the VGG19 model), it is important to freezeits layers. For example, I tried to unfreeze just the 5 last layers but the accuracy didn't exceed 93%.