SPRINT (VLDB\u201996 \u2014 J. Shafer et al.) C(Yes|No)=C(No|Yes) = q 2. "@type": "ImageObject", "description": "How to evaluate the performance of a model Methods for Performance Evaluation. 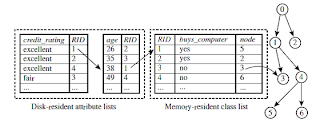 "@context": "http://schema.org", { Using ROC for Model ComparisonNo model consistently outperform the other M1 is better for small FPR M2 is better for large FPR Area Under the ROC curve Ideal: Area = 1 Random guess: Area = 0.5 BOAT (Bootstrapped Optimistic Algorithm for Tree Construction)Use a statistical technique called bootstrapping to create several smaller samples (subsets), each fits in memory Each subset is used to create a tree, resulting in several trees These trees are examined and used to construct a new tree T It turns out that T is very close to the tree that would be generated using the whole data set together Adv: requires only two scans of DB, an incremental alg. Buy_Computer. Confidence Interval for p: Z\uf061\/2. e.g: Toss a fair coin 50 times, how many heads would turn up Expected number of heads = N\uf0b4p = 50 \uf0b4 0.5 = 25. Overfitting due to Insufficient ExamplesLack of data points in the lower half of the diagram makes it difficult to predict correctly the class labels of that region - Insufficient number of training records in the region causes the decision tree to predict the test examples using other training records that are irrelevant to the classification task "@context": "http://schema.org", }, 48 "@context": "http://schema.org", { "width": "1024" Postpruning: Remove branches from a fully grown tree\u2014get a sequence of progressively pruned trees. }, 18 }, 11 "description": "Reserve 2\/3 for training and 1\/3 for testing. "name": "Distribute Instances Probability that Refund=Yes is 3\/9", Collection of Bernoulli trials has a Binomial distribution: x Bin(N, p) x: number of correct predictions, e.g: Toss a fair coin 50 times, how many heads would turn up? ACTUAL CLASS. "width": "1024" Typical stopping conditions for a node: Stop if all instances belong to the same class. xSK@~&hPRDDPC?ThSBdprPGQ8`w V{{c p 52r:Dq1gr)/uth~-Yc89/UlmI5h9Gi&eU#-;zm\fD-vrw|[=G nxv4PK"[sT0z'==Wz~oK| O}9ozE7g-& _1W~?(FFFmq% |?_n|-7AyysauVL]wwi+K`|W;stoR>O+Q;:|(|~!0(9->QBd5:g!_U55F`! 6 qu 2 ` H 0 xcdd``d2 Use a set of data different from the training data to decide which is the best pruned tree December 1, Data Mining: Concepts and Techniques. Metrics for Performance EvaluationPREDICTED CLASS ACTUAL CLASS Class=Yes Class=No a (TP) b (FN) c (FP) d (TN) Most widely-used metric: "contentUrl": "https://slideplayer.com/14933995/91/images/slide_47.jpg", Builds an index for each attribute and only class list and the current attribute list reside in memory SPRINT (VLDB96 J. Shafer et al.) "name": "Cost-Sensitive Measures", Data Mining Classification: Basic Concepts, Decision Trees, and Model Evaluation Lecture Notes for Chapter 4 Introduction to Data Mining by Tan, Steinbach, Lecture Notes for Chapter 4 (2) Introduction to Data Mining, Classification Techniques: Decision Tree Learning, Lecture Notes for Chapter 4 Part III Introduction to Data Mining. Methods for Model Comparison How to compare the relative performance among competing models? AVC-set on Student. Trim the nodes of the decision tree in a bottom-up fashion. ", yes. { { }, 28 How to compare the relative performance among competing models", "contentUrl": "https://slideplayer.com/14933995/91/images/slide_41.jpg", How to compare the relative performance among competing models? }, 36 "name": "How to Address Overfitting", "description": "Arithmetic sampling (Langley, et al) Geometric sampling (Provost et al) Effect of small sample size: Bias in the estimate. { "@type": "ImageObject", Class=Yes. "description": "Overfitting: An induced tree may overfit the training data. "@context": "http://schema.org", "width": "1024" Don\u2019t prune case 1, prune case 2. "@context": "http://schema.org", "@type": "ImageObject", }, 57 "@context": "http://schema.org", "name": "Examples of Post-pruning", Confusion Matrix: PREDICTED CLASS ACTUAL CLASS Class=Yes Class=No a b c d a: TP (true positive) b: FN (false negative) c: FP (false positive) d: TN (true negative) "name": "Practical Issues of Classification", "name": "Overfitting and Tree Pruning", Tan,Steinbach, Kumar Introduction to Data Mining 4/18/ Classification: Definition l Given a collection of records (training set) l Find a model. Cost = p (a + d) + q (b + c) = p (a + d) + q (N \u2013 a \u2013 d) = q N \u2013 (q \u2013 p)(a + d) = N [q \u2013 (q-p) \uf0b4 Accuracy] Accuracy is proportional to cost if 1. "contentUrl": "https://slideplayer.com/slide/14933995/91/images/11/Overfitting+due+to+Insufficient+Examples.jpg", "description": "Training Error (Before splitting) = 10\/30. "width": "1024" Class=No. "name": "Model Evaluation Metrics for Performance Evaluation", "@context": "http://schema.org", { "@type": "ImageObject", "@context": "http://schema.org", }, 35 { How much confidence can we place on accuracy of M1 and M2? ", Can we say M1 is better than M2 How much confidence can we place on accuracy of M1 and M2 Can the difference in performance measure be explained as a result of random fluctuations in the test set", Share buttons are a little bit lower. "name": "Cost vs Accuracy Count Cost a b c d p q PREDICTED CLASS", "@type": "ImageObject", "width": "1024" "description": "Cost Matrix. ", "contentUrl": "https://slideplayer.com/slide/14933995/91/images/62/An+Illustrative+Example.jpg", }, 58 ", "width": "1024" "contentUrl": "https://slideplayer.com/slide/14933995/91/images/21/Computing+Impurity+Measure.jpg", Low-level concepts, scattered classes, bushy classification-trees, Information-gain analysis with dimension + level, Use a statistical technique called bootstrapping to create several smaller samples (subsets), each fits in memory, Each subset is used to create a tree, resulting in several trees, These trees are examined and used to construct a new tree T, It turns out that T is very close to the tree that would be generated using the whole data set together. no. Performance of each classifier represented as a point on the ROC curve changing the threshold of algorithm, sample distribution or cost matrix changes the location of the point { Class = Yes. "@type": "ImageObject", "name": "Using ROC for Model Comparison", "@context": "http://schema.org", "@type": "ImageObject", { "contentUrl": "https://slideplayer.com/14933995/91/images/slide_51.jpg", "name": "Cost Matrix PREDICTED CLASS C(i|j) ACTUAL CLASS", "description": "Precision is biased towards C(Yes|Yes) & C(Yes|No) Recall is biased towards C(Yes|Yes) & C(No|Yes) F-measure is biased towards all except C(No|No)", Too many branches, some may reflect anomalies due to noise or outliers. }, 41 { Repeated holdout. ", ", Class=No. { "name": "Underfitting and Overfitting (Example)", "width": "1024" a. b. c. d. a: TP (true positive) b: FN (false negative) c: FP (false positive) d: TN (true negative)", "contentUrl": "https://slideplayer.com/slide/14933995/91/images/33/Model+Evaluation+Metrics+for+Performance+Evaluation.jpg", AVC-set on Age. "description": "How to obtain a reliable estimate of performance Performance of a model may depend on other factors besides the learning algorithm: Class distribution. Low-level concepts, scattered classes, bushy classification-trees. C0: 2. "@type": "ImageObject", "@type": "ImageObject", "@type": "ImageObject", Probability that Refund=Yes is 3\/9. Performance of a model may depend on other factors besides the learning algorithm: Class distribution Cost of misclassification Size of training and test sets "description": "",
"@context": "http://schema.org", { Using ROC for Model ComparisonNo model consistently outperform the other M1 is better for small FPR M2 is better for large FPR Area Under the ROC curve Ideal: Area = 1 Random guess: Area = 0.5 BOAT (Bootstrapped Optimistic Algorithm for Tree Construction)Use a statistical technique called bootstrapping to create several smaller samples (subsets), each fits in memory Each subset is used to create a tree, resulting in several trees These trees are examined and used to construct a new tree T It turns out that T is very close to the tree that would be generated using the whole data set together Adv: requires only two scans of DB, an incremental alg. Buy_Computer. Confidence Interval for p: Z\uf061\/2. e.g: Toss a fair coin 50 times, how many heads would turn up Expected number of heads = N\uf0b4p = 50 \uf0b4 0.5 = 25. Overfitting due to Insufficient ExamplesLack of data points in the lower half of the diagram makes it difficult to predict correctly the class labels of that region - Insufficient number of training records in the region causes the decision tree to predict the test examples using other training records that are irrelevant to the classification task "@context": "http://schema.org", }, 48 "@context": "http://schema.org", { "width": "1024" Postpruning: Remove branches from a fully grown tree\u2014get a sequence of progressively pruned trees. }, 18 }, 11 "description": "Reserve 2\/3 for training and 1\/3 for testing. "name": "Distribute Instances Probability that Refund=Yes is 3\/9", Collection of Bernoulli trials has a Binomial distribution: x Bin(N, p) x: number of correct predictions, e.g: Toss a fair coin 50 times, how many heads would turn up? ACTUAL CLASS. "width": "1024" Typical stopping conditions for a node: Stop if all instances belong to the same class. xSK@~&hPRDDPC?ThSBdprPGQ8`w V{{c p 52r:Dq1gr)/uth~-Yc89/UlmI5h9Gi&eU#-;zm\fD-vrw|[=G nxv4PK"[sT0z'==Wz~oK| O}9ozE7g-& _1W~?(FFFmq% |?_n|-7AyysauVL]wwi+K`|W;stoR>O+Q;:|(|~!0(9->QBd5:g!_U55F`! 6 qu 2 ` H 0 xcdd``d2 Use a set of data different from the training data to decide which is the best pruned tree December 1, Data Mining: Concepts and Techniques. Metrics for Performance EvaluationPREDICTED CLASS ACTUAL CLASS Class=Yes Class=No a (TP) b (FN) c (FP) d (TN) Most widely-used metric: "contentUrl": "https://slideplayer.com/14933995/91/images/slide_47.jpg", Builds an index for each attribute and only class list and the current attribute list reside in memory SPRINT (VLDB96 J. Shafer et al.) "name": "Cost-Sensitive Measures", Data Mining Classification: Basic Concepts, Decision Trees, and Model Evaluation Lecture Notes for Chapter 4 Introduction to Data Mining by Tan, Steinbach, Lecture Notes for Chapter 4 (2) Introduction to Data Mining, Classification Techniques: Decision Tree Learning, Lecture Notes for Chapter 4 Part III Introduction to Data Mining. Methods for Model Comparison How to compare the relative performance among competing models? AVC-set on Student. Trim the nodes of the decision tree in a bottom-up fashion. ", yes. { { }, 28 How to compare the relative performance among competing models", "contentUrl": "https://slideplayer.com/14933995/91/images/slide_41.jpg", How to compare the relative performance among competing models? }, 36 "name": "How to Address Overfitting", "description": "Arithmetic sampling (Langley, et al) Geometric sampling (Provost et al) Effect of small sample size: Bias in the estimate. { "@type": "ImageObject", Class=Yes. "description": "Overfitting: An induced tree may overfit the training data. "@context": "http://schema.org", "width": "1024" Don\u2019t prune case 1, prune case 2. "@context": "http://schema.org", "@type": "ImageObject", }, 57 "@context": "http://schema.org", "name": "Examples of Post-pruning", Confusion Matrix: PREDICTED CLASS ACTUAL CLASS Class=Yes Class=No a b c d a: TP (true positive) b: FN (false negative) c: FP (false positive) d: TN (true negative) "name": "Practical Issues of Classification", "name": "Overfitting and Tree Pruning", Tan,Steinbach, Kumar Introduction to Data Mining 4/18/ Classification: Definition l Given a collection of records (training set) l Find a model. Cost = p (a + d) + q (b + c) = p (a + d) + q (N \u2013 a \u2013 d) = q N \u2013 (q \u2013 p)(a + d) = N [q \u2013 (q-p) \uf0b4 Accuracy] Accuracy is proportional to cost if 1. "contentUrl": "https://slideplayer.com/slide/14933995/91/images/11/Overfitting+due+to+Insufficient+Examples.jpg", "description": "Training Error (Before splitting) = 10\/30. "width": "1024" Class=No. "name": "Model Evaluation Metrics for Performance Evaluation", "@context": "http://schema.org", { "@type": "ImageObject", "@context": "http://schema.org", }, 35 { How much confidence can we place on accuracy of M1 and M2? ", Can we say M1 is better than M2 How much confidence can we place on accuracy of M1 and M2 Can the difference in performance measure be explained as a result of random fluctuations in the test set", Share buttons are a little bit lower. "name": "Cost vs Accuracy Count Cost a b c d p q PREDICTED CLASS", "@type": "ImageObject", "width": "1024" "description": "Cost Matrix. ", "contentUrl": "https://slideplayer.com/slide/14933995/91/images/62/An+Illustrative+Example.jpg", }, 58 ", "width": "1024" "contentUrl": "https://slideplayer.com/slide/14933995/91/images/21/Computing+Impurity+Measure.jpg", Low-level concepts, scattered classes, bushy classification-trees, Information-gain analysis with dimension + level, Use a statistical technique called bootstrapping to create several smaller samples (subsets), each fits in memory, Each subset is used to create a tree, resulting in several trees, These trees are examined and used to construct a new tree T, It turns out that T is very close to the tree that would be generated using the whole data set together. no. Performance of each classifier represented as a point on the ROC curve changing the threshold of algorithm, sample distribution or cost matrix changes the location of the point { Class = Yes. "@type": "ImageObject", "name": "Using ROC for Model Comparison", "@context": "http://schema.org", "@type": "ImageObject", { "contentUrl": "https://slideplayer.com/14933995/91/images/slide_51.jpg", "name": "Cost Matrix PREDICTED CLASS C(i|j) ACTUAL CLASS", "description": "Precision is biased towards C(Yes|Yes) & C(Yes|No) Recall is biased towards C(Yes|Yes) & C(No|Yes) F-measure is biased towards all except C(No|No)", Too many branches, some may reflect anomalies due to noise or outliers. }, 41 { Repeated holdout. ", ", Class=No. { "name": "Underfitting and Overfitting (Example)", "width": "1024" a. b. c. d. a: TP (true positive) b: FN (false negative) c: FP (false positive) d: TN (true negative)", "contentUrl": "https://slideplayer.com/slide/14933995/91/images/33/Model+Evaluation+Metrics+for+Performance+Evaluation.jpg", AVC-set on Age. "description": "How to obtain a reliable estimate of performance Performance of a model may depend on other factors besides the learning algorithm: Class distribution. Low-level concepts, scattered classes, bushy classification-trees. C0: 2. "@type": "ImageObject", "@type": "ImageObject", "@type": "ImageObject", Probability that Refund=Yes is 3\/9. Performance of a model may depend on other factors besides the learning algorithm: Class distribution Cost of misclassification Size of training and test sets "description": "",
"description": "", How to obtain reliable estimates Methods for Model Comparison. "description": "For complex models, there is a greater chance that it was fitted accidentally by errors in data. Buy_Computer. "contentUrl": "https://slideplayer.com/slide/14933995/91/images/19/Examples+of+Post-pruning.jpg", "description": "", Since D1 and D2 are independent, their variance adds up: At (1-\uf061) confidence level,", Confidence Interval for AccuracyPrediction can be regarded as a Bernoulli trial A Bernoulli trial has 2 possible outcomes Possible outcomes for prediction: correct or wrong Collection of Bernoulli trials has a Binomial distribution: x Bin(N, p) x: number of correct predictions e.g: Toss a fair coin 50 times, how many heads would turn up? }, 60
"name": "Computing Impurity Measure", Can the difference in performance measure be explained as a result of random fluctuations in the test set? "width": "1024" 20. "contentUrl": "https://slideplayer.com/slide/14933995/91/images/20/Handling+Missing+Attribute+Values.jpg", }, 20 "width": "1024" Two approaches to avoid overfitting. "@type": "ImageObject", > v o p q r s t u `! tl%2F2 ` H 0 xcdd``d2 { "@context": "http://schema.org", }, 24 Can the difference in performance measure be explained as a result of random fluctuations in the test set? Divorced. "contentUrl": "https://slideplayer.com/slide/14933995/91/images/24/Model+Evaluation+Metrics+for+Performance+Evaluation.jpg", Confidence Interval for AccuracyConsider a model that produces an accuracy of 80% when evaluated on 100 test instances: N=100, acc = 0.8 Let 1- = 0.95 (95% confidence) From probability table, Z/2=1.96 1- Z 0.99 2.58 0.98 2.33 0.95 1.96 0.90 1.65 N 50 100 500 1000 5000 p(lower) 0.670 0.711 0.763 0.774 0.789 p(upper) 0.888 0.866 0.833 0.824 0.811 "@context": "http://schema.org", RainForest (VLDB\u201998 \u2014 Gehrke, Ramakrishnan & Ganti) Builds an AVC-list (attribute, value, class label) BOAT (PODS\u201999 \u2014 Gehrke, Ganti, Ramakrishnan & Loh) Uses bootstrapping to create several small samples. { "contentUrl": "https://slideplayer.com/slide/14933995/91/images/25/Model+Evaluation+Metrics+for+Performance+Evaluation.jpg", "description": "Cost(Model,Data) = Cost(Data|Model) + Cost(Model) Cost is the number of bits needed for encoding. ", }, 27 }, 45 Affects how to distribute instance with missing value to child nodes. Class=No Class=Yes. M1 is better for small FPR. "@type": "ImageObject", Model M2: accuracy = 75%, tested on 5000 instances. }, 6 depicts relative trade-offs between. "contentUrl": "https://slideplayer.com/slide/14933995/91/images/61/Comparing+Performance+of+2+Models.jpg", "width": "1024" fair excellent. "width": "1024" Assessing and Comparing Classification Algorithms Introduction Resampling and Cross Validation Measuring Error Interval Estimation and Hypothesis Testing. "contentUrl": "https://slideplayer.com/slide/14933995/91/images/37/Model+Evaluation+Metrics+for+Performance+Evaluation.jpg", Probability that Marital Status = Married is 3.67\/6.67. 5. Information-gain analysis with dimension + level. Model Evaluation Metrics for Performance EvaluationHow to evaluate the performance of a model? "name": "Metrics for Performance Evaluation\u2026", 6\/ Refund. "@type": "ImageObject", Reduced error pruning? 8. "name": "", "@context": "http://schema.org", If you wish to download it, please recommend it to your friends in any social system. "name": "Methods for Performance Evaluation", Search for the least costly model. }, 38 Practical Issues of ClassificationUnderfitting and Overfitting Missing Values Costs of Classification "description": "Class=Yes. "@context": "http://schema.org", {
"@type": "ImageObject", "contentUrl": "https://slideplayer.com/14933995/91/images/slide_40.jpg", }, 51 ", Performance of each classifier represented as a point on the ROC curve. Leave-one-out: k=n. ", ", Notes on Overfitting Overfitting results in decision trees that are more complex than necessary Training error no longer provides a good estimate of how well the tree will perform on previously unseen records Need new ways for estimating errors