Apache Spark is a distributed computing system. It does so either on its own or in tandem with other distributed computing tools. Please enable Strictly Necessary Cookies first so that we can save your preferences! 50 GB of Snapshots Free to Use for One Year, SALES: 888-618-3282
If you disable this cookie, we will not be able to save your preferences. How to Configure Git Username and Email Address, Free From Epic Games Exclusivity, Metro Exodus Is Coming To Linux, Atlassian Fixes Critical Flaws in Confluence, Jira, Bitbucket, Others, 9 Best Free Website Downtime Monitoring Services, Dell XPS 13 Plus (Developer Edition) Gets Certified for Ubuntu 22.04 LTS, LibreOffice 7.3.5 Office Suite Released with 83 Bug Fixes, Download Now.
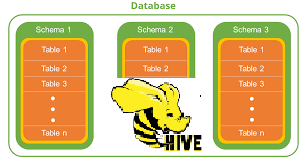
This snap installs Spark 2.1.1 and is compatible with Apache Bigtop 1.2.0.
Verified account, Publisher: Postman, Inc. 20/10/02 10:45:12 INFO ResourceUtils: ==============================================================
In this tutorial, we will show you how to install an Apache Spark standalone cluster on CentOS 8. This compensation may impact how and where products appear on this site including, for example, the order in which they appear. Want to publish your own application? It consists of a master and one or more slaves, where the master distributes the work among the slaves, thus giving the ability to use our many computers to work on one task. Ensure that sparkadm has permissions to write to this directory, Assuming Python is installed under /usr/bin/ and is available as /usr/bin/python3, Spark tar is downloaded to path /home/downloads. or One could guess that this is indeed a powerful tool where tasks need large computations to complete, but can be split into smaller chunks of steps that can be pushed to the slaves to work on. They update automatically and roll back gracefully.
Sharing how technologies are making an impact on the way we work, live and play, Senior Data Scientist, Cloud Solutions Architect @Cisco, Decorators in Python: Fundamentals for Data Scientists.
Spark is a Java-based application, so you will need to install Java in your system. 50 GB of Snapshots Free to Use for One Year. Verified account, Publisher: Slack Spark also features an easy-to-use API, reducing the programming burden associated with data crunching. These two qualities make it particularly useful in the world of machine learning and big data. foobar2000 is an advanced freeware audio player.
Our thriving international community engages with us through social media and frequent content contributions aimed at solving problems ranging from personal computing to enterprise-level IT operations.
 You can also check cluster status at http://
You can also check cluster status at http://:8080/. Apache Spark is a data processing framework that performs processing tasks over large data sets quickly.
2022 Canonical Ltd. 20/10/02 10:45:12 INFO ResourceUtils: Resources for spark.worker: 20/10/02 10:45:12 INFO ResourceUtils: ============================================================== How RAID Arrays Keep Your Data Safe and Accessible, Top 10 Best Cybersecurity Training Services, A fresh CentOS 8 Desktop on the Atlantic.Net Cloud Platform, A root password configured on your server.
First, log in to your Atlantic.Net Cloud Server. Create a new server, choosing CentOS 8 as the operating system, with at least 4 GB RAM. Once an application is submitted check the same at http://:4040/. 20/10/02 10:45:12 INFO TransportClientFactory: Successfully created connection to /45.58.32.165:7077 after 66 ms (0 ms spent in bootstraps)
G3.2GB Cloud VPS Server Free to Use for One Year Verified account. Keeping this cookie enabled helps us to improve our website.
This will show errors in detail when there is a failure, 11. Protecting Patient Data: the Right Way and the Wrong Way! 17. Check for Spark installation under /home/spark on all nodes. You can install the Java using the following command: Once Java is installed, you can verify the Java version with the following command: You should get the Java version in the following output: First, you will need to download the latest version of Spark from its official website. How do I get started with Yurbi Professional Services? Update /home/ansible/SparkAnsible/hosts/host with master and worker node names, 4. Now, start the Slave service and enable it to start at boot with the following command: Next, check the status of the Slave with the following command: You can also check the Spark slave log file for confirmation: 20/10/02 10:45:12 INFO Worker: Spark home: /opt/spark Update /home/spark/conf/spark-env.sh on all nodes for SPARK_LOCAL_IP, SPARK_MASTER_HOST to point to Master IP Address. Update /home/ansible/SparkAnsible/vars/var_basic.yml for {DOWNLAOD_PATH}, {PATH_TO_PYTHON_EXE}, {HADOOP_PATH}, 6. First, create a master service file with the following command: Save and close the file when you are finished, then create a Spark slave service with the following command: Save and close the file, then reload the systemd daemon with the following command: Now, you can start the Spark master service and enable it to start at boot with the following command: You can verify the status of the Master service with the following command: You can also check the Spark log file to check the Master server. 2. Strictly Necessary Cookie should be enabled at all times so that we can save your preferences for cookie settings.
Verified account, The best email app for people and teams at work, Publisher: Spotify
50 GB of Block Storage Free to Use for One Year
Snapcraft, At this point, the Spark master server is started and listening on port 8080. G3.2GB Cloud VPS Free to Use for One Year In this guide, you learned how to set up a single node Spark cluster on CentOS 8. 15. You can download it with the following command: Once the download is completed, extract the downloaded file with the following command: Next, move the extracted directory to /opt with the following command: Next, create a separate user to run Spark with the following command: Next, change the ownership of the /opt/spark directory to the spark user with the following command: Next, you will need to create a systemd service file for the Spark master and slave. This website uses analytics software to collect anonymous information such as the number of visitors to the site and the most popular pages. Update /home/ansible/SparkAnsible/ansible.cfg for PATH_TO_PYTHON_EXE,PATH_TO_HOSTS_FILE, 6. You can update your cookie settings at any time. Tracking Email Opens with Gmail, Sheets, and Apps Script, Length of Shortest sub-array containing k distinct elements of another Array | Sliding Window, Databricks Certified Developer for Apache Spark Scala Exam Questions, Time-based batch processing architecture using Apache Spark, and ClickHouse, Operating System : Red Hat Enterprise Linux Server release 7.6 (Maipo), iptables -I INPUT -p tcp --dport 9000 -j ACCEPT, iptables -I INPUT -p tcp dport 50010 -j ACCEPT, ansible_python_interpreter: /usr/bin/python3, export SPARK_MASTER_HOST=, export PYSPARK_DRIVER_PYTHON=/usr/bin/python, https://github.com/vsdeepthi/SparkAnsible.git, https://www.apache.org/dyn/closer.lua/spark/spark-3.1.2/spark-3.1.2-bin-hadoop3.2.tgz, Password-less ssh is setup between the hosts for user sparkadm, /home is the path where the installation will happen.
Powered by Charmed Kubernetes. Ubuntu and Canonical are registered trademarks of Canonical Ltd. Apache Spark is a fast and general engine for large-scale data processing. 20/10/02 10:45:12 INFO WorkerWebUI: Bound WorkerWebUI to 0.0.0.0, and started at http://centos8:8081
16.
You should see the worker in the following page.
This means that every time you visit this website you will need to enable or disable cookies again. Free Tier Includes:
TechnologyAdvice does not include all companies or all types of products available in the marketplace. Once our cluster is up and running, we can write programs to run on it in Python, Java, and Scala. You can now configure Spark multinode cluster easily and use it for big data and machine learning processing.
Update /home/ansible/SparkAnsible/vars/user.yml for GENERIC_USER & GENERIC_USER_GROUP, 5.
Verified account. Update {MASTER_IP}, {MASTER_HOSTNAME} in /home/ansible/SparkAnsible/vars/var_master.yml, /home/ansible/SparkAnsible/vars/var_workers.yml, 8.
this site. Interested to find out more about snaps? Snaps are applications packaged with all their dependencies to run on all popular Linux distributions from a single build. 2022 Atlantic.Net, All Rights Reserved. On worker nodes as root enable port 50010, 3.
If you continue to use this site, you consent to our use of cookies and our Privacy Policy. Free Tier includes: Verified account, Publisher: Mailspring This post assumes that you are setting up the cluster using a generic user id say sparkadm. 20/10/02 10:45:12 INFO Worker: Connecting to master 45.58.32.165:7077 Now, open your web browser and access the Spark dashboard using the URL http://your-server-ip:8080. We use cookies for advertising, social media and analytics purposes.
The packages for RHEL 8 and RHEL 7 are in each distributions respective Extra Packages for Enterprise Linux (EPEL) repository. 20/10/02 10:45:13 INFO Worker: Successfully registered with master spark://centos8:7077. The instructions for adding this repository diverge slightly between RHEL 8 and RHEL 7, which is why theyre listed separately below. LinuxToday serves as a home for a community that struggles to find comparable information elsewhere on the web. You can download the tar from. You can also access the worker directly using the URL http://your-server-ip:8081. We Provide Cloud, Dedicated, & Colocation. Verified account, Publisher: Canonical snapd, Snap is available for Red Hat Enterprise Linux (RHEL) 8 and RHEL 7, from the 7.6 release onward. INTL: +1-321-206-3734. Now, go to the Spark dashboard and reload the page.
Advertiser Disclosure: Some of the products that appear on this site are from companies from which TechnologyAdvice receives compensation. Apache Spark can also distribute data processing tasks across several computers.
To learn more about our use of cookies, please visit our Privacy Policy. We use cookies for advertising, social media and analytics purposes. Snaps are discoverable and installable from the Snap Store, an app store with an audience of millions. Publisher: Inkscape Project Set up Apache Spark on your VPS hosting account with Atlantic.Net!
LinuxToday is a trusted, contributor-driven news resource supporting all types of Linux users. Once you are logged in to your CentOS 8 server, run the following command to update your base system with the latest available packages. 12.
Enable Ansible debugger. On how to do the same please refer to this link. 50 GB of Block Storage Free to Use for One Year
Ensure you have setup a passwordless ssh between the hosts in the cluster for this user id sparkadm belonging to linux group spark. You can use jps command to check if the deamons have started. Read about how we use cookies in our updated Privacy Policy. Browse and find snaps from the convenience of your desktop using the snap store snap. Visit snapcraft.io now. Connect to your Cloud Server via SSH and log in using the credentials highlighted at the top of the page. To install spark, simply use the following command: Privacy-oriented voice, video, chat, and conference platform and SIP phone, Publisher: Stichting Krita Foundation The EPEL repository can be added to RHEL 8 with the following command: The EPEL repository can be added to RHEL 7 with the following command: Adding the optional and extras repositories is also recommended: Once installed, the systemd unit that manages the main snap communication socket needs to be enabled: To enable classic snap support, enter the following to create a symbolic link between /var/lib/snapd/snap and /snap: Either log out and back in again or restart your system to ensure snaps paths are updated correctly. You should see the Spark dashboard in the following page: In the above page, there are no workers attached to the master. Join the forum, contribute to or report problems with, 20/10/02 10:45:12 INFO Utils: Successfully started service WorkerUI on port 8081. It undertakes most of the work associated with big data processing and distributed computing. Update /home/ansible/SparkAnsible/roles/spark/tasks/main.yml for PATH_TO_PYTHON_EXE, 7.
If you disable this cookie, we will not be able to save your preferences. How to Configure Git Username and Email Address, Free From Epic Games Exclusivity, Metro Exodus Is Coming To Linux, Atlassian Fixes Critical Flaws in Confluence, Jira, Bitbucket, Others, 9 Best Free Website Downtime Monitoring Services, Dell XPS 13 Plus (Developer Edition) Gets Certified for Ubuntu 22.04 LTS, LibreOffice 7.3.5 Office Suite Released with 83 Bug Fixes, Download Now.
This snap installs Spark 2.1.1 and is compatible with Apache Bigtop 1.2.0.
Verified account, Publisher: Postman, Inc. 20/10/02 10:45:12 INFO ResourceUtils: ==============================================================
In this tutorial, we will show you how to install an Apache Spark standalone cluster on CentOS 8. This compensation may impact how and where products appear on this site including, for example, the order in which they appear. Want to publish your own application? It consists of a master and one or more slaves, where the master distributes the work among the slaves, thus giving the ability to use our many computers to work on one task. Ensure that sparkadm has permissions to write to this directory, Assuming Python is installed under /usr/bin/ and is available as /usr/bin/python3, Spark tar is downloaded to path /home/downloads. or One could guess that this is indeed a powerful tool where tasks need large computations to complete, but can be split into smaller chunks of steps that can be pushed to the slaves to work on. They update automatically and roll back gracefully.
Sharing how technologies are making an impact on the way we work, live and play, Senior Data Scientist, Cloud Solutions Architect @Cisco, Decorators in Python: Fundamentals for Data Scientists.
Spark is a Java-based application, so you will need to install Java in your system. 50 GB of Snapshots Free to Use for One Year. Verified account, Publisher: Slack Spark also features an easy-to-use API, reducing the programming burden associated with data crunching. These two qualities make it particularly useful in the world of machine learning and big data. foobar2000 is an advanced freeware audio player.
Our thriving international community engages with us through social media and frequent content contributions aimed at solving problems ranging from personal computing to enterprise-level IT operations.
You can also check cluster status at http://2022 Canonical Ltd. 20/10/02 10:45:12 INFO ResourceUtils: Resources for spark.worker: 20/10/02 10:45:12 INFO ResourceUtils: ============================================================== How RAID Arrays Keep Your Data Safe and Accessible, Top 10 Best Cybersecurity Training Services, A fresh CentOS 8 Desktop on the Atlantic.Net Cloud Platform, A root password configured on your server.
First, log in to your Atlantic.Net Cloud Server. Create a new server, choosing CentOS 8 as the operating system, with at least 4 GB RAM. Once an application is submitted check the same at http://
G3.2GB Cloud VPS Server Free to Use for One Year Verified account. Keeping this cookie enabled helps us to improve our website.
This will show errors in detail when there is a failure, 11. Protecting Patient Data: the Right Way and the Wrong Way! 17. Check for Spark installation under /home/spark on all nodes. You can install the Java using the following command: Once Java is installed, you can verify the Java version with the following command: You should get the Java version in the following output: First, you will need to download the latest version of Spark from its official website. How do I get started with Yurbi Professional Services? Update /home/ansible/SparkAnsible/hosts/host with master and worker node names, 4. Now, start the Slave service and enable it to start at boot with the following command: Next, check the status of the Slave with the following command: You can also check the Spark slave log file for confirmation: 20/10/02 10:45:12 INFO Worker: Spark home: /opt/spark Update /home/spark/conf/spark-env.sh on all nodes for SPARK_LOCAL_IP, SPARK_MASTER_HOST to point to Master IP Address. Update /home/ansible/SparkAnsible/vars/var_basic.yml for {DOWNLAOD_PATH}, {PATH_TO_PYTHON_EXE}, {HADOOP_PATH}, 6. First, create a master service file with the following command: Save and close the file when you are finished, then create a Spark slave service with the following command: Save and close the file, then reload the systemd daemon with the following command: Now, you can start the Spark master service and enable it to start at boot with the following command: You can verify the status of the Master service with the following command: You can also check the Spark log file to check the Master server. 2. Strictly Necessary Cookie should be enabled at all times so that we can save your preferences for cookie settings.
Verified account, The best email app for people and teams at work, Publisher: Spotify
50 GB of Block Storage Free to Use for One Year
Snapcraft, At this point, the Spark master server is started and listening on port 8080. G3.2GB Cloud VPS Free to Use for One Year In this guide, you learned how to set up a single node Spark cluster on CentOS 8. 15. You can download it with the following command: Once the download is completed, extract the downloaded file with the following command: Next, move the extracted directory to /opt with the following command: Next, create a separate user to run Spark with the following command: Next, change the ownership of the /opt/spark directory to the spark user with the following command: Next, you will need to create a systemd service file for the Spark master and slave. This website uses analytics software to collect anonymous information such as the number of visitors to the site and the most popular pages. Update /home/ansible/SparkAnsible/ansible.cfg for PATH_TO_PYTHON_EXE,PATH_TO_HOSTS_FILE, 6. You can update your cookie settings at any time. Tracking Email Opens with Gmail, Sheets, and Apps Script, Length of Shortest sub-array containing k distinct elements of another Array | Sliding Window, Databricks Certified Developer for Apache Spark Scala Exam Questions, Time-based batch processing architecture using Apache Spark, and ClickHouse, Operating System : Red Hat Enterprise Linux Server release 7.6 (Maipo), iptables -I INPUT -p tcp --dport 9000 -j ACCEPT, iptables -I INPUT -p tcp dport 50010 -j ACCEPT, ansible_python_interpreter: /usr/bin/python3, export SPARK_MASTER_HOST=
Powered by Charmed Kubernetes. Ubuntu and Canonical are registered trademarks of Canonical Ltd. Apache Spark is a fast and general engine for large-scale data processing. 20/10/02 10:45:12 INFO WorkerWebUI: Bound WorkerWebUI to 0.0.0.0, and started at http://centos8:8081
16.
You should see the worker in the following page.
This means that every time you visit this website you will need to enable or disable cookies again. Free Tier Includes:
TechnologyAdvice does not include all companies or all types of products available in the marketplace. Once our cluster is up and running, we can write programs to run on it in Python, Java, and Scala. You can now configure Spark multinode cluster easily and use it for big data and machine learning processing.
Update /home/ansible/SparkAnsible/vars/user.yml for GENERIC_USER & GENERIC_USER_GROUP, 5.
Verified account. Update {MASTER_IP}, {MASTER_HOSTNAME} in /home/ansible/SparkAnsible/vars/var_master.yml, /home/ansible/SparkAnsible/vars/var_workers.yml, 8.
this site. Interested to find out more about snaps? Snaps are applications packaged with all their dependencies to run on all popular Linux distributions from a single build. 2022 Atlantic.Net, All Rights Reserved. On worker nodes as root enable port 50010, 3.
If you continue to use this site, you consent to our use of cookies and our Privacy Policy. Free Tier includes: Verified account, Publisher: Mailspring This post assumes that you are setting up the cluster using a generic user id say sparkadm. 20/10/02 10:45:12 INFO Worker: Connecting to master 45.58.32.165:7077 Now, open your web browser and access the Spark dashboard using the URL http://your-server-ip:8080. We use cookies for advertising, social media and analytics purposes.
The packages for RHEL 8 and RHEL 7 are in each distributions respective Extra Packages for Enterprise Linux (EPEL) repository. 20/10/02 10:45:13 INFO Worker: Successfully registered with master spark://centos8:7077. The instructions for adding this repository diverge slightly between RHEL 8 and RHEL 7, which is why theyre listed separately below. LinuxToday serves as a home for a community that struggles to find comparable information elsewhere on the web. You can download the tar from. You can also access the worker directly using the URL http://your-server-ip:8081. We Provide Cloud, Dedicated, & Colocation. Verified account, Publisher: Canonical snapd, Snap is available for Red Hat Enterprise Linux (RHEL) 8 and RHEL 7, from the 7.6 release onward. INTL: +1-321-206-3734. Now, go to the Spark dashboard and reload the page.
Advertiser Disclosure: Some of the products that appear on this site are from companies from which TechnologyAdvice receives compensation. Apache Spark can also distribute data processing tasks across several computers.
To learn more about our use of cookies, please visit our Privacy Policy. We use cookies for advertising, social media and analytics purposes. Snaps are discoverable and installable from the Snap Store, an app store with an audience of millions. Publisher: Inkscape Project Set up Apache Spark on your VPS hosting account with Atlantic.Net!
LinuxToday is a trusted, contributor-driven news resource supporting all types of Linux users. Once you are logged in to your CentOS 8 server, run the following command to update your base system with the latest available packages. 12.
Enable Ansible debugger. On how to do the same please refer to this link. 50 GB of Block Storage Free to Use for One Year
Ensure you have setup a passwordless ssh between the hosts in the cluster for this user id sparkadm belonging to linux group spark. You can use jps command to check if the deamons have started. Read about how we use cookies in our updated Privacy Policy. Browse and find snaps from the convenience of your desktop using the snap store snap. Visit snapcraft.io now. Connect to your Cloud Server via SSH and log in using the credentials highlighted at the top of the page. To install spark, simply use the following command: Privacy-oriented voice, video, chat, and conference platform and SIP phone, Publisher: Stichting Krita Foundation The EPEL repository can be added to RHEL 8 with the following command: The EPEL repository can be added to RHEL 7 with the following command: Adding the optional and extras repositories is also recommended: Once installed, the systemd unit that manages the main snap communication socket needs to be enabled: To enable classic snap support, enter the following to create a symbolic link between /var/lib/snapd/snap and /snap: Either log out and back in again or restart your system to ensure snaps paths are updated correctly. You should see the Spark dashboard in the following page: In the above page, there are no workers attached to the master. Join the forum, contribute to or report problems with, 20/10/02 10:45:12 INFO Utils: Successfully started service WorkerUI on port 8081. It undertakes most of the work associated with big data processing and distributed computing. Update /home/ansible/SparkAnsible/roles/spark/tasks/main.yml for PATH_TO_PYTHON_EXE, 7.