Whenever we are trying to create a DF from a backward-compatible object like RDD or a data frame created by spark session, you need to make your SQL context-aware about your session and context. 3.1. sparkhadoop. Memory overhead is the amount of off-heap memory allocated to each executor. The spark-submit command is a utility to run or submit a Spark or PySpark application program (or job) to the cluster by specifying options and configurations, the application you are submitting can be written in Scala, Java, or Python (PySpark). ; spark.executor.cores: Number of cores per executor. Not a necessary property to set, unless theres a reason to use less cores than available for a given Spark session. The sample notebook Spark job on Apache spark pool defines a simple machine learning pipeline. Scenario: Livy Server fails to start on Apache Spark cluster Issue. In the below example, I am extracting the 4th column (3rd index) from Specify the desired Spark-submit options. Spark. where SparkContext is initialized, in the same format as JVM memory strings with a size unit suffix ("k", "m", "g" or "t") (e.g. Select spark in the Prefix list, then add "spark.master" in the Key field and the setting in the Value field. Tune the number of executors and the memory and core usage based on resources in the cluster: executor-memory, num-executors, and executor-cores. Tune the available memory to the driver: spark.driver.memory. spark.driver.cores: 1: Number of cores to use for the driver process, only in cluster mode. spark spark . sparklyr.shell.driver-memory - The limit is the amount of RAM available in the computer minus what would be needed for OS operations.
1.2.0: spark.driver.memory: 1g Check out the configuration documentation for the Spark release you are working with and use the appropriate parameters.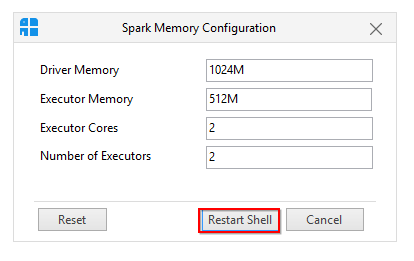 If not specified, this will look for conf/spark-defaults. As you see above output, PySpark DataFrame collect() returns a Row Type, hence in order to convert DataFrame Column to Python List first, you need to select the DataFrame column you wanted using rdd.map() lambda expression and then collect the DataFrame. Having a high limit may cause out-of-memory errors in driver (depends on spark.driver.memory and memory overhead of objects in JVM). Low driver memory configured as per the application requirements. IDM H&S committee meetings for 2022 will be held via Microsoft Teams on the following Tuesdays at 12h30-13h30: 8 February 2022; 31 May 2022; 2 August 2022 First, the notebook defines a data preparation step powered by the synapse_compute defined in the previous step. Create a SynapseSparkStep that uses the linked Apache Spark pool. rdd3. spark.driver.memory: Amount of memory to use for the driver process, i.e. Note that properties like spark.hadoop.
If not specified, this will look for conf/spark-defaults. As you see above output, PySpark DataFrame collect() returns a Row Type, hence in order to convert DataFrame Column to Python List first, you need to select the DataFrame column you wanted using rdd.map() lambda expression and then collect the DataFrame. Having a high limit may cause out-of-memory errors in driver (depends on spark.driver.memory and memory overhead of objects in JVM). Low driver memory configured as per the application requirements. IDM H&S committee meetings for 2022 will be held via Microsoft Teams on the following Tuesdays at 12h30-13h30: 8 February 2022; 31 May 2022; 2 August 2022 First, the notebook defines a data preparation step powered by the synapse_compute defined in the previous step. Create a SynapseSparkStep that uses the linked Apache Spark pool. rdd3. spark.driver.memory: Amount of memory to use for the driver process, i.e. Note that properties like spark.hadoop. 
1000M, 2G) (Default: 512M). The entry point into SparkR is the SparkSession which connects your R program to a Spark cluster. 512m Each applications memory requirement is different. Further, you can also work with SparkDataFrames via SparkSession.If you are working from the sparkR shell, the SparkSession where SparkContext is initialized. Should be at least 1M, or 0 for unlimited. Cluster mode In cluster mode, the driver will run on one of the worker nodes. Kubernetes an open-source system for automating deployment, scaling, and The Spark RAPIDS accelerator is a plugin that works by overriding the physical plan of a Spark job by supported GPU operations, and running those operations on the GPUs, thereby accelerating processing. Configuration property details.
The entry point into SparkR is the SparkSession which connects your R program to a Spark cluster. 512m Each applications memory requirement is different. Further, you can also work with SparkDataFrames via SparkSession.If you are working from the sparkR shell, the SparkSession where SparkContext is initialized. Should be at least 1M, or 0 for unlimited. Cluster mode In cluster mode, the driver will run on one of the worker nodes. Kubernetes an open-source system for automating deployment, scaling, and The Spark RAPIDS accelerator is a plugin that works by overriding the physical plan of a Spark job by supported GPU operations, and running those operations on the GPUs, thereby accelerating processing. Configuration property details.
Install New -> PyPI -> spark-nlp-> Install 3.2. I resolved this issue by setting spark.driver.memory to a number that suits my driver's memory (for 32GB ram I set it to 18G). spark.memory.fraction -
spark-submit command supports the following. To understand the difference between Cluster & Client Deployments, read this post.. s ="" // say the n-th column spark.executor.memory: Amount of memory to use per executor process. ; Apache Mesos Mesons is a Cluster manager that can also run Hadoop MapReduce and Spark applications. ; Hadoop YARN the resource manager in Hadoop 2.This is mostly used, cluster manager. Configure the Spark Driver Memory Allocation in Cluster Mode. Similarly, you can tune --executor-cores and --driver-memory. As obvious as it may seem, this is one of the hardest things to get right. 12--driver-memory: Memory for driver (e.g. You should ensure correct spark.executor.memory or spark.driver.memory values depending on the workload. The amount of memory requested by Spark at initialization is configured either in spark-defaults.conf, or through the command line. Misconfiguration of spark.sql.autoBroadcastJoinThreshold. By default, memory overhead is set to either 10% of executor memory or 384, whichever is higher.
Install New -> Maven -> Coordinates -> com.johnsnowlabs.nlp:spark-nlp_2.12:4.0.1-> Install Now you can attach your notebook to the cluster and use Spark NLP! For more information about spark-submit options, see Launching applications with spark-submit. Jobs will be aborted if the total size is above this limit. Standalone a simple cluster manager included with Spark that makes it easy to set up a cluster. NOTE: Databricks runtimes support different Apache Spark major A Spark job progress indicator is provided with a real-time progress bar appears to help you understand the job execution status. The number of tasks per each job or stage help you to identify the parallel level of your spark job. spark.driver.memory can be set as the same as spark.executor.memory, just like spark.driver.cores is set as the same as spark.executors.cores. ; spark.yarn.executor.memoryOverhead: The amount of off heap memory (in megabytes) to be allocated per executor, when running Spark on Yarn.This is memory that accounts for things The Apache Hadoop YARN, HDFS, Spark, and other file-prefixed properties are applied at the cluster level when you create a cluster. deploy-mode: It denotes where you want to deploy your driver on the worker nodes (cluster) or locally as an external client (client) (default: client).). Depending on the requirement, each app has to be configured differently. This mode is preferred for Production Run of a Spark Applications Setting a proper limit can protect the driver from out-of-memory errors. In a step, you would provide the following arguments to rddapi3.1 1. rdd rddsparkrdd If I add any one of the below flags, then the run-time drops to around 40-50 seconds and the difference is coming from the drop in GC times:--conf "spark.memory.fraction=0.6" OR--conf "spark.memory.useLegacyMode=true" OR--driver-java-options "-XX:NewRatio=3" All the other cache types except for DISK_ONLY produce similar symptoms. You can create a SparkSession using sparkR.session and pass in options such as the application name, any spark packages depended on, etc. 512m, 2g). Setting is configured based on the instance types in the cluster. But the truth is the dynamic resource allocation doesn't set the driver memory and keeps it to its default value, which is 1G. spark.driver.memory: 1g: Amount of memory to use for the driver process, i.e. The name of spark application. Add the following property to change the Spark History Server memory from 1g to 4g: SPARK_DAEMON_MEMORY=4g. (for example, 1g, 2g). Make sure to restart all affected services from Ambari. 13--driver-java-options: Extra Java options to pass to the driver. Spark. Executor & Driver memory. Apache Spark - Deployment, Spark application, using spark-submit, is a shell command used to deploy the Spark application on a cluster. Livy Server cannot be started on an Apache Spark [(Spark 2.1 on Linux (HDI 3.6)]. The second part Spark Properties lists the application properties like spark.app.name and spark.driver.memory. 1. In Libraries tab inside your cluster you need to follow these steps:. This tutorial explains how to read or load from and write Spark (2.4.X version) DataFrame rows to HBase table using hbase-spark connector and Datasource "org.apache.spark.sql.execution.datasources.hbase" along with Scala example. Spark action(collect)1m0driver spark.driver.memory JVM spark.driver.memory. DirectDNA is a neural network model to directly predict the nucleic acid sequences of DNA fragments. Hello everyone, Lately, one of the HBase libraries used in this article has been changed in the Maven repository From spark-defaults.conf Clicking the Hadoop Properties link displays properties relative to Hadoop and YARN. Submitting Spark application on different cluster managers Another prominent property is spark.default.parallelism, and can be estimated with the help of the following formula.
In cluster mode, the Spark Driver runs inside YARN Application Master. DirectDNA provides a new framework to extract latent information from raw DNA sequencing data. Convert DataFrame Column to Python List. It is recommended 23 tasks per CPU core in the cluster. rdd2. 1.
Spark 1jdkjdk 2HadoopHadoop 3ScalaLinuxScala Spark 1 s is the string of column values .collect() converts columns/rows to an array of lists, in this case, all rows will be converted to a tuple, temp is basically an array of such tuples/row.. x(n-1) retrieves the n-th column value for x-th row, which is by default of type "Any", so needs to be converted to String so as to append to the existing strig. * are shown Cluster vs. Job Properties.
1.2.0: spark.driver.memory: 1g Check out the configuration documentation for the Spark release you are working with and use the appropriate parameters.
If not specified, this will look for conf/spark-defaults. As you see above output, PySpark DataFrame collect() returns a Row Type, hence in order to convert DataFrame Column to Python List first, you need to select the DataFrame column you wanted using rdd.map() lambda expression and then collect the DataFrame. Having a high limit may cause out-of-memory errors in driver (depends on spark.driver.memory and memory overhead of objects in JVM). Low driver memory configured as per the application requirements. IDM H&S committee meetings for 2022 will be held via Microsoft Teams on the following Tuesdays at 12h30-13h30: 8 February 2022; 31 May 2022; 2 August 2022 First, the notebook defines a data preparation step powered by the synapse_compute defined in the previous step. Create a SynapseSparkStep that uses the linked Apache Spark pool. rdd3. spark.driver.memory: Amount of memory to use for the driver process, i.e. Note that properties like spark.hadoop. 1000M, 2G) (Default: 512M).
Install New -> PyPI -> spark-nlp-> Install 3.2. I resolved this issue by setting spark.driver.memory to a number that suits my driver's memory (for 32GB ram I set it to 18G). spark.memory.fraction -
spark-submit command supports the following. To understand the difference between Cluster & Client Deployments, read this post.. s ="" // say the n-th column spark.executor.memory: Amount of memory to use per executor process. ; Apache Mesos Mesons is a Cluster manager that can also run Hadoop MapReduce and Spark applications. ; Hadoop YARN the resource manager in Hadoop 2.This is mostly used, cluster manager. Configure the Spark Driver Memory Allocation in Cluster Mode. Similarly, you can tune --executor-cores and --driver-memory. As obvious as it may seem, this is one of the hardest things to get right. 12--driver-memory: Memory for driver (e.g. You should ensure correct spark.executor.memory or spark.driver.memory values depending on the workload. The amount of memory requested by Spark at initialization is configured either in spark-defaults.conf, or through the command line. Misconfiguration of spark.sql.autoBroadcastJoinThreshold. By default, memory overhead is set to either 10% of executor memory or 384, whichever is higher.
Install New -> Maven -> Coordinates -> com.johnsnowlabs.nlp:spark-nlp_2.12:4.0.1-> Install Now you can attach your notebook to the cluster and use Spark NLP! For more information about spark-submit options, see Launching applications with spark-submit. Jobs will be aborted if the total size is above this limit. Standalone a simple cluster manager included with Spark that makes it easy to set up a cluster. NOTE: Databricks runtimes support different Apache Spark major A Spark job progress indicator is provided with a real-time progress bar appears to help you understand the job execution status. The number of tasks per each job or stage help you to identify the parallel level of your spark job. spark.driver.memory can be set as the same as spark.executor.memory, just like spark.driver.cores is set as the same as spark.executors.cores. ; spark.yarn.executor.memoryOverhead: The amount of off heap memory (in megabytes) to be allocated per executor, when running Spark on Yarn.This is memory that accounts for things The Apache Hadoop YARN, HDFS, Spark, and other file-prefixed properties are applied at the cluster level when you create a cluster. deploy-mode: It denotes where you want to deploy your driver on the worker nodes (cluster) or locally as an external client (client) (default: client).). Depending on the requirement, each app has to be configured differently. This mode is preferred for Production Run of a Spark Applications Setting a proper limit can protect the driver from out-of-memory errors. In a step, you would provide the following arguments to rddapi3.1 1. rdd rddsparkrdd If I add any one of the below flags, then the run-time drops to around 40-50 seconds and the difference is coming from the drop in GC times:--conf "spark.memory.fraction=0.6" OR--conf "spark.memory.useLegacyMode=true" OR--driver-java-options "-XX:NewRatio=3" All the other cache types except for DISK_ONLY produce similar symptoms. You can create a SparkSession using sparkR.session and pass in options such as the application name, any spark packages depended on, etc. 512m, 2g). Setting is configured based on the instance types in the cluster. But the truth is the dynamic resource allocation doesn't set the driver memory and keeps it to its default value, which is 1G. spark.driver.memory: 1g: Amount of memory to use for the driver process, i.e. The name of spark application. Add the following property to change the Spark History Server memory from 1g to 4g: SPARK_DAEMON_MEMORY=4g. (for example, 1g, 2g). Make sure to restart all affected services from Ambari. 13--driver-java-options: Extra Java options to pass to the driver. Spark. Executor & Driver memory. Apache Spark - Deployment, Spark application, using spark-submit, is a shell command used to deploy the Spark application on a cluster. Livy Server cannot be started on an Apache Spark [(Spark 2.1 on Linux (HDI 3.6)]. The second part Spark Properties lists the application properties like spark.app.name and spark.driver.memory. 1. In Libraries tab inside your cluster you need to follow these steps:. This tutorial explains how to read or load from and write Spark (2.4.X version) DataFrame rows to HBase table using hbase-spark connector and Datasource "org.apache.spark.sql.execution.datasources.hbase" along with Scala example. Spark action(collect)1m0driver spark.driver.memory JVM spark.driver.memory. DirectDNA is a neural network model to directly predict the nucleic acid sequences of DNA fragments. Hello everyone, Lately, one of the HBase libraries used in this article has been changed in the Maven repository From spark-defaults.conf Clicking the Hadoop Properties link displays properties relative to Hadoop and YARN. Submitting Spark application on different cluster managers Another prominent property is spark.default.parallelism, and can be estimated with the help of the following formula.
In cluster mode, the Spark Driver runs inside YARN Application Master. DirectDNA provides a new framework to extract latent information from raw DNA sequencing data. Convert DataFrame Column to Python List. It is recommended 23 tasks per CPU core in the cluster. rdd2. 1.
Spark 1jdkjdk 2HadoopHadoop 3ScalaLinuxScala Spark 1 s is the string of column values .collect() converts columns/rows to an array of lists, in this case, all rows will be converted to a tuple, temp is basically an array of such tuples/row.. x(n-1) retrieves the n-th column value for x-th row, which is by default of type "Any", so needs to be converted to String so as to append to the existing strig. * are shown Cluster vs. Job Properties.